




- @qq_16949707
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
1 pixel accuracy (PA,像素精度)就是 每一类像素,正确分类的像素的个数 的和 / 每一类像素的实际的像素的个数之和。2 mean pixel accuracy (MPA, 均像素精度)每一类像素的精度的平均值,即先求出每一类像素的PA,然后再取平均值。3 Mean Intersection over Union(MIoU, 均交并比)反正就是交集除以并集然后...
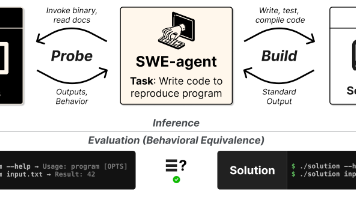
arXiv:2605.03546v1 (预印本标识)John Yang, Kilian Lieret, Jeffrey Ma, Parth Thakkar 等总结1: 评估范式由SWE-bench的修bug改为直接重建整个项目。现有的代码大模型评估(如SWE-bench)陷入了“填空题”和“局部修补”的瓶颈。ProgramBench首创了“黑盒逆向工程+从零构建”的范式,强迫AI承担真正的“软件架
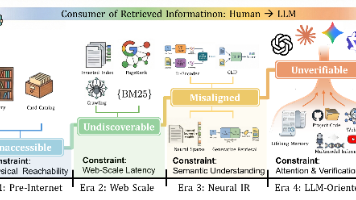
摘要: 港科大团队在SIGIR 2026发表的论文《LLM-Oriented Information Retrieval: A Denoising-First Perspective》提出,大模型时代信息检索的核心矛盾已从“召回不足”转向“噪声过剩”。研究揭示,LLM作为检索结果的主要消费者,对噪声极其敏感——即使检索到正确答案,多余噪声仍会导致模型性能显著下降(实验显示噪声可使Exact Mat
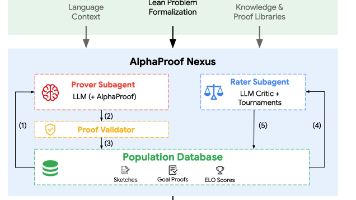
George Tsoukalas, Anton Kovsharov, Sergey Shirobokov, 等 (Google DeepMind, Aarhus University, Google)结论1: AI 已经能解决高难度的前沿数学问题。就算基础的Agent都已经具备了自主攻克封尘数十年、具有极高学术价值的数学开放难题(如保罗·埃尔德什的猜想)的能力,标志着 AI 数学向真实科研级别跨越
arXiv:2605.03546v1 (预印本标识)John Yang, Kilian Lieret, Jeffrey Ma, Parth Thakkar 等总结1: 评估范式由SWE-bench的修bug改为直接重建整个项目。现有的代码大模型评估(如SWE-bench)陷入了“填空题”和“局部修补”的瓶颈。ProgramBench首创了“黑盒逆向工程+从零构建”的范式,强迫AI承担真正的“软件架
std::vector<std::string> split(std::string s, std::string delimiter){std::vector<std::string> tokens;size_t pos = 0;std::string token;while ((pos = s.find(delimiter)) != std::string::npos)
1 综述Semantic Segmentation using Fully Convolutional Networks over the yearsJun 1, 2017https://meetshah1995.github.io/semantic-segmentation/deep-learning/pytorch/visdom/2017/06/01/semantic-segmen...
1 安装1.1 安装dockerbrew cask install docker1.2 拉取kaggle镜像,目前只有cpu版本的docker run --rm -it kaggle/python2 运行2.1 运行jupyter-notebookdocker run -v $PWD:/tmp/working -w=/tmp/working -p 8888:8888 --rm -...
1 安装1.1 安装dockerbrew cask install docker1.2 拉取kaggle镜像,目前只有cpu版本的docker run --rm -it kaggle/python2 运行2.1 运行jupyter-notebookdocker run -v $PWD:/tmp/working -w=/tmp/working -p 8888:8888 --rm -...
用WFST来表征ASR中的模型(HCLG),可以更方便的对这些模型进行融合和优化,于是可以作为一个简单而灵活的ASR的解码器(simple and flexible ASR decoder design)。利用WFTS,我们可以吧ctc label,lexicon(字典),language models(语言模型)等模型结合起来,生成一个简单的search graph用于解码。WFTS主要由