




- @qq_16511607
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍了如何利用Dify开源平台打造一个能与用户对话的"张飞"角色扮演AI。文章首先对比了Dify的Chatflow和Workflow两种工作流类型,说明Chatflow更适合对话类应用。接着详细讲解了环境准备、知识库创建等前期工作,并重点演示了如何通过组合开始节点、知识检索节点、LLM节点等构建完整的Chatflow流程。文中还提供了优化对话体验的进阶技巧,如意图判断分支和

本文介绍了一个基于FastAPI+Dify+MySQL的AI智能体系统,针对教育服务行业的痛点需求提供自动化解决方案。系统包含客服智能体、内部员工智能体和周报生成工作流,支持客户自动研判、24小时客服应答、内部知识查询及日报周报生成。技术架构采用Dify进行AI流程编排,FastAPI处理后端数据持久化,MySQL存储客户与日报数据。系统通过可视化配置实现无代码开发,已在CentOS 7虚拟机部署
本文为RAG开发者和Milvus初学者提供了一份实用指南,重点介绍了768维密集向量和BM25稀疏向量的索引选型策略,以及四种文档切片方法的对比。在Milvus索引方面,详细解析了HNSW、IVF_FLAT等不同索引的适用场景,推荐生产环境使用HNSW+COSINE组合。在文档切片方面,对比了固定规则、滑动窗口、AI辅助和概要生成四种方法,给出不同场景下的配置建议。文章特别强调实际开发中的注意事项
本文介绍了在Windows Docker环境下部署Neo4j图数据库的完整流程,包括环境准备、容器启动、常见问题解决等。详细讲解了Neo4j的核心概念(节点、关系、属性)和Cypher查询语言,并通过学生-老师-课程案例演示了基本操作。文章还对比了Neo4j与关系型数据库的特点和适用场景:关系型数据库适合结构化数据和简单关联,而Neo4j擅长处理复杂多层关系查询和路径分析。最后强调两者并非替代关系
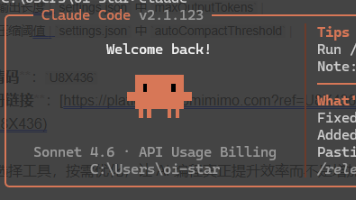
本文介绍了如何通过小米Token Plan使用Claude Code的详细教程和成本优化策略。主要内容包括:小米Token Plan的特点(按量付费、价格透明、兼容Claude);环境配置步骤(安装Claude Code、使用CC-Switch工具或手动配置);以及10项经过验证的Token优化方法,如排除无关文件、编写CLAUDE.md固化知识、使用压缩命令等,可显著降低使用成本。文末还提供了常
本文完整记录了Python包发布到PyPI的全流程,重点分享了实际经验中的常见错误和解决方案。从项目结构准备、配置文件编写、本地构建检查,到TestPyPI预发布和正式上线,每个步骤都提供了具体操作方法和注意事项。特别强调了许可证格式、版本号一致性、API token使用等易错点,并汇总了常见问题排查表。文章采用实践导向的写作方式,旨在帮助开发者避开发布过程中的"坑",顺利完成

本地部署AI Agent已经从“极客玩具”变成了人人可用的生产力工具。一句话总结:用Ollama跑本地模型,用Dify可视化编排Agent,数据不出门、不花一分钱、无限次使用。下一步行动安装Ollama并下载模型安装Docker Desktop克隆Dify并启动服务在Dify中配置Ollama模型并创建你的第一个Agent📌关于文中提到的开源项目GitHub地址汇总Ollama:Dify:Ope
如果你读到这里,已经对NLP的前三个时代有了清晰的认知。规则写不完 → 让机器从数据中学 → 但看不到长距离 → 引入记忆(RNN/LSTM)→ 但串行计算慢且长序列遗忘 → 下一步是什么?Attention(注意力机制)和 Transformer。它们放弃了循环结构,让模型可以并行计算且全局看任意位置——这正是2017年《Attention Is All You Need》论文带来的革命。你的兴
本地部署AI Agent已经从“极客玩具”变成了人人可用的生产力工具。一句话总结:用Ollama跑本地模型,用Dify可视化编排Agent,数据不出门、不花一分钱、无限次使用。下一步行动安装Ollama并下载模型安装Docker Desktop克隆Dify并启动服务在Dify中配置Ollama模型并创建你的第一个Agent📌关于文中提到的开源项目GitHub地址汇总Ollama:Dify:Ope
本文介绍了如何利用Ollama和FastAPI在本地搭建具备Agent能力的AI助手,实现模型部署、API封装和工具调用的全流程。主要内容包括:1)Ollama的安装与模型下载;2)FastAPI封装REST接口;3)Agent实现工具调用的核心原理与代码示例。通过本地化部署,开发者可降低云端API成本并保障数据隐私,同时赋予大模型自主调用外部工具的能力。文章提供了详细的操作步骤和优化建议,适合希