




- @qq853632587
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
reindex是Elasticsearch提供的一个api接口,可以把数据从源ES集群导入到当前的ES集群,同样实现了数据的迁移,限于腾讯云ES的实现方式,当前版本不支持reindex操作。有时候需要将Es里面的部分数据(以index为单位)转移到另一台主机下的es中,为了避免大量重复执行之前读取数据的耗时操作,只需要将对应的ES目录下的nodes目录中的相关数据文件夹拷贝到其他主机下的es中对应
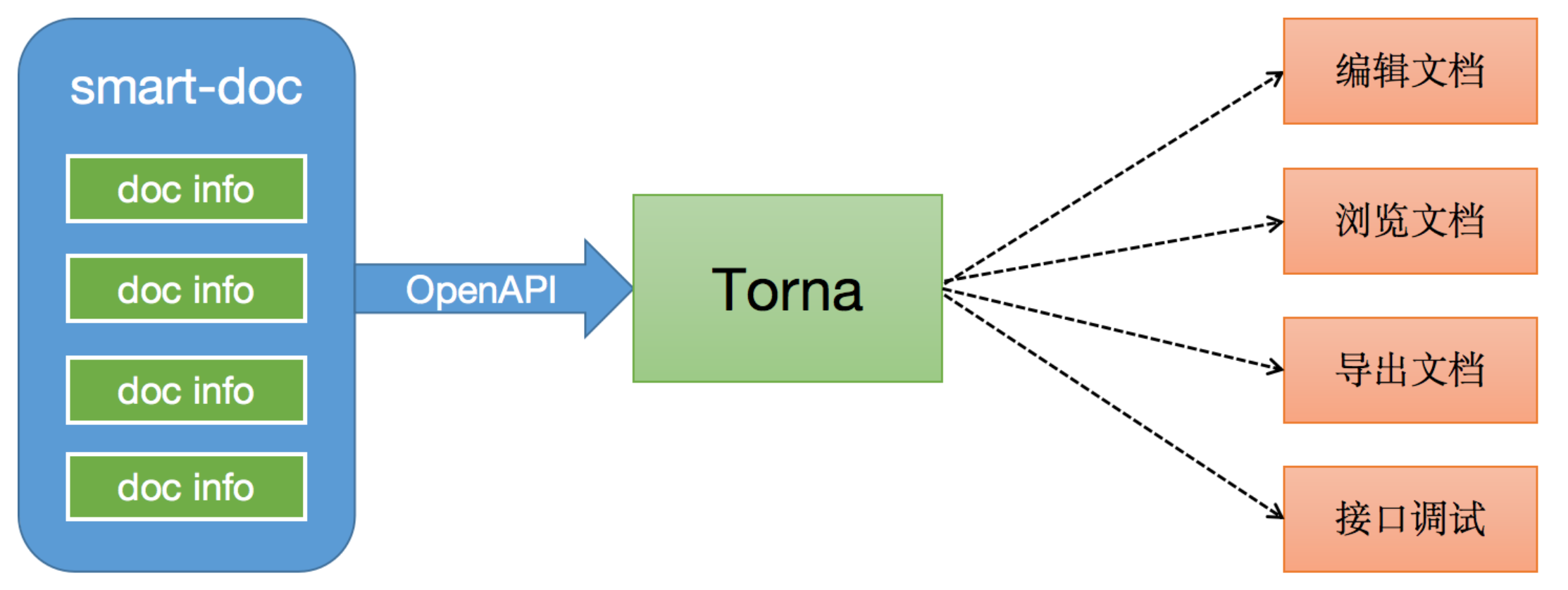
一、简介(摘要)smart-doc是一款同时支持JAVA REST API和Apache Dubbo RPC接口文档生成的工具,smart-doc在业内率先提出基于JAVA泛型定义推导的理念, 完全基于接口源码来分析生成接口文档,不采用任何注解侵入到业务代码中。你只需要按照java-doc标准编写注释, smart-doc就能帮你生成一个简易明了的Markdown、HTML5、Postman Co
整体业务流程为:客户端创建链接——>服务端保持生成SseEmitter对象,并通过SseEmitter对象实现向客户端主动推送消息——>客户端收到推送消息后,刷新页面(根据推送消息,请求相关业务接口)

由于Jquery的版本更新很快,代码的写法也改变了许多,以下Jquery代码适query1.4版本以上。1.获取选中值,三种方法都可以:$('input:radio:checked').val();$("input[type='radio']:checked").val();$("input[name='rd']:checked").val();2.设置第一个Radio为选中值:$('input:
背景最近换了个新公司接手了一个老项目,然后比较坑的是这个公司的项目都没有没有做多环境打包配置,每次发布一个环境都要手动的去修改配置文件。今天正好有空就来配置下。解决这个问题的方式有很多,我这里挑选了一个个人比较喜欢的方案,通过 maven profile 打包的时候按照部署环境打包不同的配置,下面说下具体的操作配置不同环境的配置文件建立对应的环境目录,我这里有三个环境分别是,dev/test/pr
目录1.官方api1.Scroll概念2.Client support for scrolling and reindexing(滚动搜索和索引之间的文档重索引)3.基本用法1.Keeping the search context alive2.Clear scroll API3.Sliced Scroll3.实现分页案例1.实现分页,每页20条数据,第一次请求返回第一页数据2.使用scroll_
大多数ElasticSearch用户在创建索引时通用会问的一个重要问题是:我需要创建多少个分片?在本文中, 我将介绍在分片分配时的一些权衡以及不同设置带来的性能影响. 如果想搞清晰你的分片策略以及如何优化,请继续往下阅读.为什么要考虑分片数分片分配是个很重要的概念, 很多用户对如何分片都有所疑惑, 当然是为了让分配更合理. 在生产环境中, 随着数据集的增长, 不合理的分配策略可能会给系统的扩展带来
目录1.官方api1.Scroll概念2.Client support for scrolling and reindexing(滚动搜索和索引之间的文档重索引)3.基本用法1.Keeping the search context alive2.Clear scroll API3.Sliced Scroll3.实现分页案例1.实现分页,每页20条数据,第一次请求返回第一页数据2.使用scroll_
es 实现sql的 group by后如何分页?先放json解释,再放纯净版方便copy{"query": {...... //搜索条件},"aggs": {"count": {// COUNT(*),统计GROUP BY后的总数"cardinality": {"field": "goods_id"// 因为我这里GROUP BY的字段是goods_id,所以
curl -XPUT http://127.0.0.1:9200/rtiaes/_settings -d '{ "index" : { "max_result_window" : 2147483647}}'注意:1.size的大小不能超过index.max_result_window这个参数的设置,默认为10,000。2.需要搜索分页,可以通过from size组合来进行。from表示从第几行开始