




- @qiantianye
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
文章摘要 本文从新手视角系统讲解Git与GitHub在深度学习项目中的使用。首先介绍了Git作为版本控制工具的核心功能,以及GitHub作为远程托管平台的作用。然后详细阐述了WSL Ubuntu环境下Git工作流程,包括本地项目目录、Git仓库与远程仓库的关系。针对深度学习项目特点,重点说明为何不应将数据集、模型权重等大文件上传至GitHub,并推荐使用.gitignore文件进行过滤。文章通过四
BLIP-2 通过冻结图像编码器和大语言模型,只训练中间的 Q-Former,实现低成本视觉语言对齐。Q-Former 利用 learnable queries 从图像特征中提取关键信息,再通过两阶段训练完成图文对齐与文本生成适配,是连接视觉模型与 LLM 的经典桥接方案。

本文介绍了LLaVA(Large Language and Vision Assistant)模型,提出了一种视觉指令微调方法(Visual Instruction Tuning)。LLaVA通过连接CLIP视觉编码器和Vicuna语言模型,构建了一个能理解图像并遵循自然语言指令的多模态助手。论文创新性地利用GPT-4生成了158K高质量的视觉指令数据,包含对话、详细描述和复杂推理三类任务。模型采
摘要 论文《PatentGPT: A Large Language Model for Intellectual Property》提出了一套面向知识产权领域的领域大模型训练流程,而非全新架构。针对知识产权领域三大核心挑战——专业知识强、隐私要求高、文本极长,研究团队以LLaMA2/Mixtral等开源模型为基础,通过240B+token的IP领域数据继续预训练、指令微调(SFT)、强化学习对齐(
摘要 GPT-3论文《Language Models are Few-Shot Learners》开创性地展示了大规模语言模型通过上下文学习(In-Context Learning)的能力。研究表明,当模型参数量达到1750亿时,仅需在prompt中提供任务说明和少量示例(Few-shot),无需微调即可完成多种NLP任务。这种Decoder-only架构的Transformer模型通过单向注意力

这篇文章详细讲解了LLaMA模型的Transformer Block架构,主要包括以下核心内容: LLaMA采用Decoder-only Transformer结构,通过自回归方式预测下一个token。 每层Transformer Block由两个主要部分组成: Attention和 FFN/MLP。RMSNorm,causal attention,旋转位置编码 RoPE,SwiGLU,等
本文介绍了InstructGPT如何通过人类反馈微调语言模型,使其输出更符合用户意图。核心方法分为三步:首先用人工标注的高质量答案对GPT-3进行监督微调(SFT);然后训练奖励模型(RM),通过人类对多个回答的排序学习偏好;最后使用近端策略优化(PPO)算法,让语言模型根据RM的分数不断优化输出。这种SFT+RM+PPO的范式解决了GPT-3仅追求文本续写而忽视用户真实需求的问题,使模型能更好地

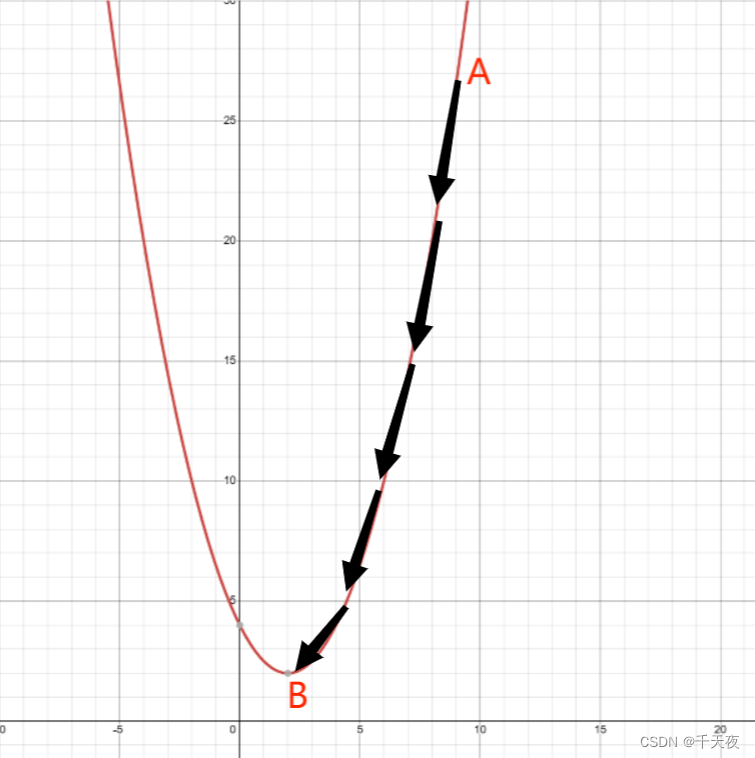
本文深入解析了LLaMA模型的核心优势——"小模型,充分训练"策略。通过对比GPT-3和LLaMA-13B的表现,揭示了大模型并非越大越好,关键在于合理配比参数量与训练数据量。文章重点阐释了Chinchilla Scaling Law的经验法则(D≈20N),指出LLaMA通过超量训练(如7B模型训练1T tokens)实现模型能力的充分激发。同时介绍了LLaMA采用的公开数据集组合及其对应能力培

机器学习(归一化、去中心化、标准化)
版本检测头结构关键技术优势缺点YOLOv1全连接层(FC)无速度快,设计简单,适合实时检测精度低,定位不准确,小物体检测能力差YOLOv2多卷积层 + passthrough更好的精度,适应不同尺寸物体,改进了小物体检测计算复杂度增加,锚框选择依赖数据YOLOv3多卷积层 + 跨层特征融合多尺度预测,特征金字塔(FPN)多尺度检测,精度更高,尤其是小物体检测计算开销大,推理速度较慢通过YOLOv1
