




- @python123456_
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本部分旨在建立 Prompt Engineering 与 Context Engineering 的基础概念,清晰地界定二者之间的区别与联系。从前者到后者的转变,代表了人工智能应用开发领域一次关键的演进——从业界最初关注的战术性指令构建,转向由可扩展、高可靠性系统需求驱动的战略性架构设计。一个提示(Prompt)远不止一个简单的问题,它是一个结构化的输入,可包含多个组成部分。对模型的核心任务指令,

这里先用一小段篇幅带大家快速了解下Coze并进入到指定操作界面。Coze 是字节跳动推出的零代码或低代码智能体开发平台,基于其大模型技术,提供插件系统、长短期记忆、工作流编排等核心能力,支持多模态交互(文本/语音/图像)与多平台发布(如豆包、飞书、Discord),专注构建个人助理、电商客服、内容生成等场景的智能体应用。
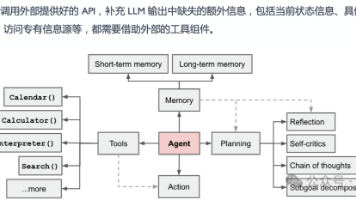
智能体(Agent)作为先进的人工智能实体,通过持续感知外部环境、自主决策并执行行动来达成预设目标。其架构具备环境感知、动态决策、行为执行等核心功能模块,并集成记忆存储机制、多层级规划策略及工具调用能力。其规划模块整合了思维链推演、自我反思机制及目标分解技术,形成闭环式认知增强系统。区别于传统AI系统,智能体展现出三大核心特性:在独立运作层面具有无需人工干预的决策自主性;在时间维度上支持长期运行与
在大模型浪潮席卷各行各业的今天,Java 作为企业级开发的绝对主力,如何无缝接入 AI 能力成为开发者关注的焦点。Spring AI 的诞生,正是为 Java 生态提供了统一、简洁、面向生产的大模型集成方案。本文将带你从零开始,基于 Spring Boot 3 + Spring AI + Ollama + MCP Client,搭建一个支持 本地大模型调用 与 工具函数调用(Function Ca
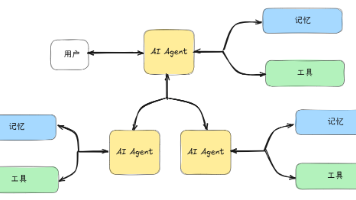
AI Agent,即人工智能代理,是一种能够感知环境、进行决策和执行动作的智能实体。从定义来看,它有着深厚的发展渊源,其起源可以追溯到哲学领域。早在古希腊时期,哲学家们就对智能机器产生了浓厚的兴趣,像赫拉克利特斯提出的 “自动机” 概念,就为后来的 AI 研究奠定了思想基础。公元前 350 年左右的亚里士多德时期,哲学家们在哲学作品中描述过一些拥有欲望、信念、意图和采取行动能力的实体,这也被视作

DeepSeekLLM,旨在通过长期视角推动开源语言模型的发展。数据收集与预处理:首先,开发了一个包含2万亿token的数据集,并对其进行去重、过滤和重新混合。去重阶段通过跨多个dump进行去重,过滤阶段通过详细的语义和语言学评估来增强数据密度,重新混合阶段则通过增加代表性不足领域的存在来平衡数据。表1|各种常见 Crawl dumps 去重比率。

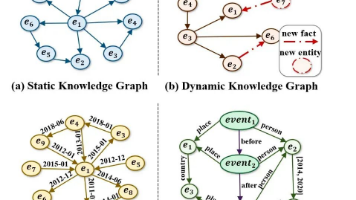
知识图谱从静态、动态、时态到事件驱动的演变反映了AI系统的进步。大型语言模型通过自动化实体识别、关系提取和事件检测,增强了知识图谱的构建和推理能力。这种融合使AI代理能够发展情景记忆,实现更复杂的推理和适应不断变化的环境。知识图谱与LLM的协同作用正在重新定义智能系统的未来,增强其学习和适应能力。知识图谱(KG)的发展与人工智能(AI)代理的进步紧密相连。从它们的静态起源开始,知识图谱已经发展到包
DeepSeek-V3.2-Exp是基于V3.1-Terminus的改进版本,引入DeepSeek Sparse Attention(DSA)机制,实现长文本处理效率提升2-3倍,内存使用降低30-40%,API成本降低50%以上。模型在保持与前代相当性能的同时,显著降低了计算资源消耗。已在Hugging Face和ModelScope开源,适用于长文本处理、代码生成、逻辑推理等场景,为开发者提供

同时课程详细介绍了。
