




- @pageniao
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
1. 问题描述使用SpringBoot创建一个模块,IDEA没有识别出来,如下图所示显示的都是灰色:2. 解决方法2.1 选中模块单击右键,选择【Remove Module】2.2 如下图所示找到模块所在目录,选中即可
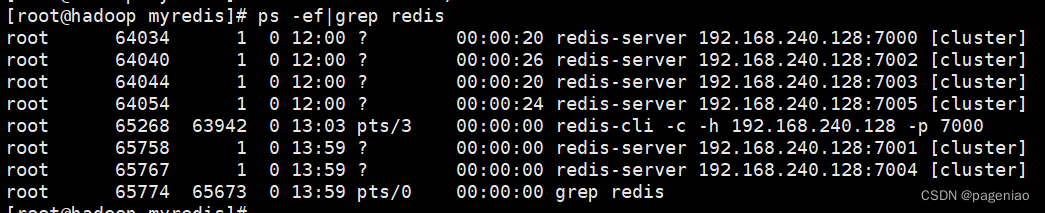
6个进程主从分配如下。
Window 环境连接虚拟机中Hadoop及Spark集群1.Windows安装Hadoop1.1 配置环境变量1.2 下载相似版本的文件1.Windows安装Hadoop在windows上把hadoop的压缩包解压到一个没有空格的目录下,比如是D盘根目录1.1 配置环境变量HADOOP_HOME=D:\hadoop-2.7.7Path下添加 %HADOOP_HOME%\bin1.2 下载相似版本
1. 精确一次消费1.2 定义精确一次消费(Exactly-once) 是指消息一定会被处理且只会被处理一次。不多不少就一次处理。如果达不到精确一次消费,可能会达到另外两种情况:至少一次消费(at least once),主要是保证数据不会丢失,但有可能存在数据重复问题。最多一次消费 (at most once),主要是保证数据不会重复,但有可能存在数据丢失问题。如果同时解决了数据丢失和数据重复的
1. 现象各节点发送/接收数据量都是0可以看到各节点是链接在一起的2. 原因整个流程各operator task的并行度相同,而Flink默认不监控与外界数据源的输入输出,可以把中间算子的并行度设为相同的就可以看到中间数据QPS;可以看到各节点的operator task是分开连接在一起的,这样会显示各节点的QPS,由于我的是测试的数据不是kafka一直有数,所以过段时间QPS又降为0了。...
@python1. 安装第三方库是报错pip._vendor.urllib3.exceptions.ReadTimeoutError: HTTPSConnectionPool(host=‘files.pythonhosted.org’, port=443): Read timed out.解决方法:pip --default-timeout=100 install 库名称 -i http://py
在程序已经稳定运行多天、未对代码做任何修改、查看所消费数据源未出现数据增多的情况下,有一个flink程序最近出现了积压问题,很是疑惑,观察几天并查看了日志发现,每当出现加压时便会伴随该日志出现,因此便着手解决该问题。...
1.问题问题简介及背景在使用Flink自带的Kafka消费API时,我们可以像单纯的使用Kafka消费对象API对其进行相应的属性设置,例如,读取offset的方式、设置offset的方式等。但是,Flink具有checkpoint功能,保存各运算算子的状态,也包括消费kafka时的offset,那这两种情况分别在什么时候起作用呢?2. Flink checkpoint设置flink并不依赖kaf