




- @newcar2025
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
具身智能开发者一站式资源中心,信息资讯,教育培训,资料下载,供应链集成、研发服务。
本报告基于全球7800亿美元组件市场预期,揭秘人形机器人从技术验证迈向商业化的核心逻辑:组件供应商率先受益,行业进入整合洗牌期,为投资者、产业链从业者、行业观察者提供全景式指南。
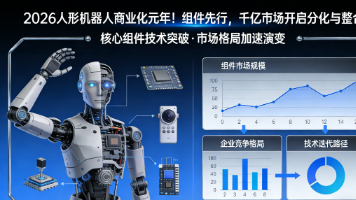
高盛最新报告指出,中国人形机器人行业放弃短期通用型目标,转向导购、导游、展览引导等 “专用型” 服务娱乐场景,优必选、小鹏等企业率先落地。国内供应链乐观扩产(规划 10 万 - 100 万台产能),优必选 2026 年产能将达 5000 台(本地化率 90%),但行业 90% 依赖英伟达等美国芯片,自主化需求迫切,北京已关注潜在产能泡沫风险。

中国车企蔚来宣布开放自研 NX9031 自动驾驶芯片技术授权,该芯片采用 5nm 工艺、集成 500 亿晶体管,算力达英伟达 Orin-X 的 4 倍,已搭载于 ET9 车型。蔚来联合芯擎科技、豪威集团成立合资公司,将技术拓展至机器人等非车领域,通过授权模式回收数十亿研发投入,助力 2026 年非 GAAP 盈利目标。

魔法原子机器人获艾普兰金奖,京东发布智能机器人产业加速2.0计划,Robotaxi在深圳实现单车盈利

本指南系统的梳理环境清洁、安全巡检、物流配送、零售服务、导览接待、康养陪护、智慧停车、城市保障等11个核心场景,覆盖商业综合体、医院、社区、交通枢纽等20多个城市空间。明确各场景硬件要求、环境适配标准、应用流程及预期成果,融合SLAM导航、AI视觉识别、多模态交互等前沿技术,提供从产品选型、系统集成到运营管理的全流程参考,助力企业研发落地、城市数字化转型,是智能机器人规模化应用的权威实操手册。

本报告基于全球7800亿美元组件市场预期,揭秘人形机器人从技术验证迈向商业化的核心逻辑:组件供应商率先受益,行业进入整合洗牌期,为投资者、产业链从业者、行业观察者提供全景式指南。
波士顿动力 Atlas 人形机器人真实世界测试曝光(CBS 60 分钟报道),此次测试暴露出四大问题,直击全球人形机器人行业共性痛点。本文深度拆解问题本质,给出硬件升级、续航优化、智能升级等具体破局建议,助力行业从实验室走向量产商用。

宇树发布全球首款量产载人变形机甲;爱思唯尔起诉Meta盗版论文训练大模型;马斯克起诉OpenAI索赔1500亿

本文将深度解析DreamZero的技术突破、二次预训练范式的核心内涵,拆解其在数据利用、跨具身迁移上的独特优势,详解英伟达如何通过GB200架构破解实时性难题,剖析其对机器人行业的颠覆性影响,为技术从业者、行业观察者、投资者呈现最专业、最全面的深度解读。

星动纪元融资10亿,OpenAI发布GPT-5.4,银河通用落子厦门,智元酷拓推动6G+四足机器人
