




- @moment8aVry
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
然后将"facebookresearch/dinov2"修改为你的本地路径"path/to/your/dinov2_main"。首先根据项目名称("facebookresearch/dinov2")将项目下载到本地,并传至服务器上。挂载服务器时,无法连接github,从而无法在线加载模型。最后添加一个参数“source”

(3)这里一般的方法是构建软链接,让系统默认使用的动态链接库指向~/environment/miniconda3/lib/libstdc++.so.6,但是这种方法需要sudo权限,我没有权限,所以我直接修改环境配置。(2)查看miniconda3/lib下的的libstdc++.so动态链接库是否有CXXABI_1.3.8,如果依旧没有就说明版本依旧不够新,只能换方法,先去安装新版本,我没有操作

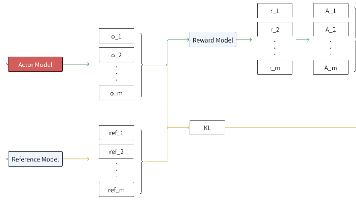
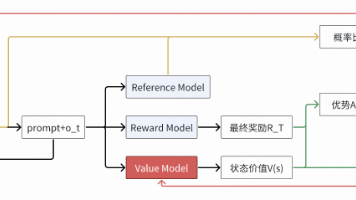
文章对比了强化学习中的PPO与GRPO算法在LLM场景下的差异。PPO依赖人类偏好数据,但易导致模型"刷分"行为,且需维护多个模型,资源消耗大。GRPO通过多策略并行、仅计算最终奖励、无监督训练等方式改进:1)取消中间奖励计算,激发模型自主推理;2)采用优胜劣汰策略选择替代梯度优化;3)保留基础SFT训练解决冷启动问题。GRPO的目标函数包含策略优势计算和KL正则项,平衡创新与基础能力保持。该方法
LeNet模型使用的激活函数是Sigmoid函数,优化器采用Momentum。AlexNet模型使用的激活函数是ReLU函数,优化器是Adam。上述结构是针对手写数字识别任务而设计。二、AlexNet模型。

一句话:在当前状态(State)下,智能体(Agent)与环境(Environment)交互,并采取动作(Action)进入下一状态,过程中获得奖励(Reward,有正向有负向),从而实现从环境中学习。在LLM场景下,提到RL一般是指RLHF(人类偏好对齐),此时上述关键概念介绍如下:Agent:语言模型本身,例如GPT、LLaMA。Environment: 训练阶段,环境是奖励模型RM,它基于人
(3)这里一般的方法是构建软链接,让系统默认使用的动态链接库指向~/environment/miniconda3/lib/libstdc++.so.6,但是这种方法需要sudo权限,我没有权限,所以我直接修改环境配置。(2)查看miniconda3/lib下的的libstdc++.so动态链接库是否有CXXABI_1.3.8,如果依旧没有就说明版本依旧不够新,只能换方法,先去安装新版本,我没有操作
将g++安装在新的文件夹gcc-5.4中,另外在gcc-5.4文件夹内新建了一个compilefile文件夹用来存储g++编译过程产生的文件。理论经过上述配置之后执行gcc -v和g++ -v得到的就是你安装的最新版本号。对于第二个报错,是由于目前使用的c++编译器与pytorch的编译器不一致。对于第一个报错,是由于g++版本过低,需要安装5.0以上版本。2、修改环境变量,指定编译器为g++(1
LeNet模型使用的激活函数是Sigmoid函数,优化器采用Momentum。AlexNet模型使用的激活函数是ReLU函数,优化器是Adam。上述结构是针对手写数字识别任务而设计。二、AlexNet模型。
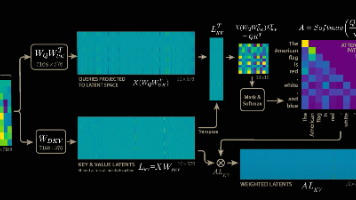
这样的问题是参数的共享会导致模型效果下降,毕竟原本有128个头,128份KV参数,每份KV参数都会计算出不一样的注意力分布,让模型能更好的根据所有的注意力分布去预测下一个词,而现在128份参数变成了1份,预测效果下降是必然的。说不存在W_UK和W_UV其实并不严谨,但是这样可以更方便去理解,其实这里所谓的把W_UK与W_Q融合是指输入先经过W_Q,紧跟着就经过W_UK,从结果上来看,跟先把W_UK
文章对比了强化学习中的PPO与GRPO算法在LLM场景下的差异。PPO依赖人类偏好数据,但易导致模型"刷分"行为,且需维护多个模型,资源消耗大。GRPO通过多策略并行、仅计算最终奖励、无监督训练等方式改进:1)取消中间奖励计算,激发模型自主推理;2)采用优胜劣汰策略选择替代梯度优化;3)保留基础SFT训练解决冷启动问题。GRPO的目标函数包含策略优势计算和KL正则项,平衡创新与基础能力保持。该方法