




- @milu_ELK
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
上述空间转换过程被我们称为一个MVP变换,M代表model,V代表view,P代表projection投影。顶点着色器最基本的任务就是将顶点从模型空间转换到裁剪空间,也就是需要在顶点着色器中实现MVP变换。

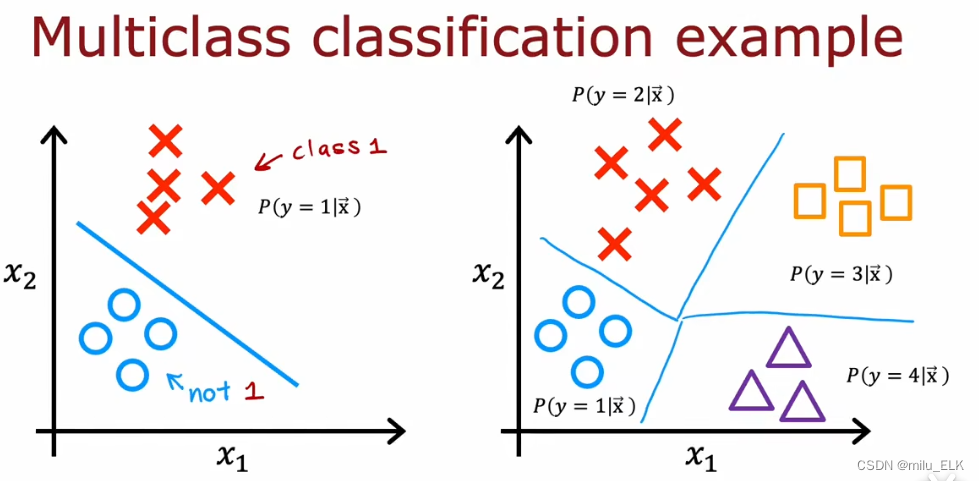
在之前的课程中,我们学习了二分问题,二分问题中的所有数据会被分类为0和1(或者Ture和False)两种输出标签。但是在大多数情况下,分类问题的输出远远不止两种情况,例如之前在课程中举例的肿瘤问题,肿瘤被分为良性和恶性两种,但实际上会有更多的分类情况,它有可能是A型,B型,C型…我们将这种拥有2种以上输出标签的问题称为多分类问题。虽然输出y依旧只能取值有限的离散值,但是输出标签的种类将会有两个以上
上述空间转换过程被我们称为一个MVP变换,M代表model,V代表view,P代表projection投影。顶点着色器最基本的任务就是将顶点从模型空间转换到裁剪空间,也就是需要在顶点着色器中实现MVP变换。
在整个神经网络模型的选择上我们也是这样测试的,例如这三个模型的隐藏层,我们计算得到二号模型的参数对应的验证误差较小,那么我们就可以使用第二个神经网络训练的参数,如果想要得到泛化误差的估计值,我们就可以用这个参数带入计算测试误差。较低,代表了训练误差低,这是必然的,因为我们是基于训练集的数据来最小化代价函数进行参数选择的,因此拟合出来的函数的训练误差一定是较小的。那么假如,我们按照刚才的模型评估的步

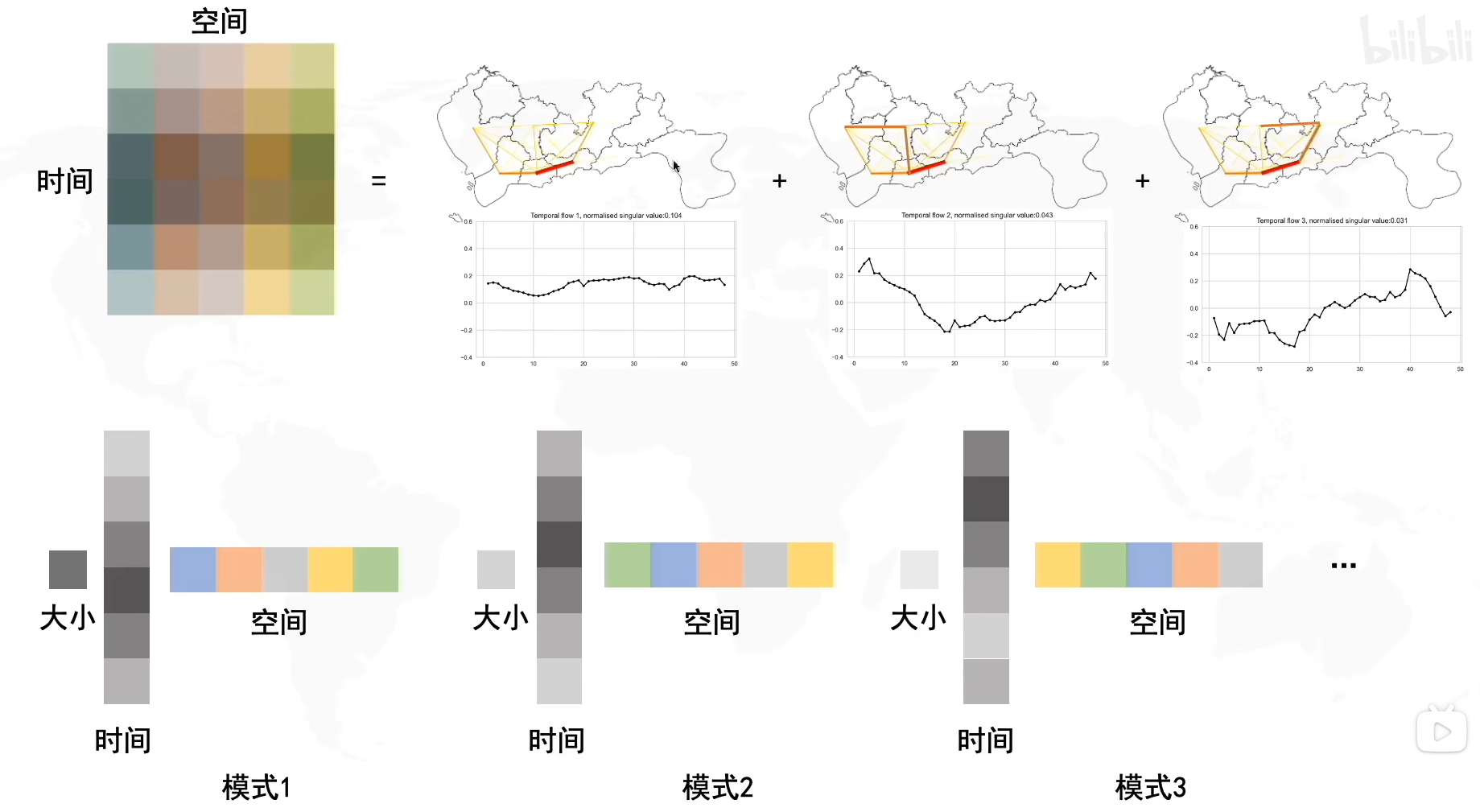
左图中的M是一个线性变换矩阵,想要从一个单位圆达到M这个效果,你可以想象一下,我们就是把这个圆拉长并且旋转。我们可以把整个操作分解为拉伸+旋转。在奇异值分解中,则是分解为了旋转VTV^TVT+拉伸Σ\SigmaΣ+旋转UUU,奇异值分解的公式则是MUΣVTMUΣVT。因此,想要解决PCA问题,我们需要找到旋转矩阵RRR,那么怎么找到它呢?我们需要协方差矩阵的帮助。
在Unity中,由于游戏是单线程的(这是为了其他线程不阻塞进程),因此我们常常需要使用协程。

匿名函数声明需要配合委托使用,并且声明时需要在函数头加上delegate,匿名函数的无参构造可以省略括号。匿名函数定义不允许使用泛型(很好理解,泛型是为了函数调用时能够灵活地接受不同类型的参数,但是使用匿名函数意味着它只会被调用一次,与其使用泛型不如让我们直接指定)定义带参数的匿名函数只需像正常函数定义即可。如果需要返回值只需使用Funcreturn q;lambda表达式就是匿名函数的一种创建方

本节课还是相当简单易懂的,该笔记也就是照抄文案然后加上自己的一些理解,推荐看李老师的原视频。
在之前的课程中,我们学习了二分问题,二分问题中的所有数据会被分类为0和1(或者Ture和False)两种输出标签。但是在大多数情况下,分类问题的输出远远不止两种情况,例如之前在课程中举例的肿瘤问题,肿瘤被分为良性和恶性两种,但实际上会有更多的分类情况,它有可能是A型,B型,C型…我们将这种拥有2种以上输出标签的问题称为多分类问题。虽然输出y依旧只能取值有限的离散值,但是输出标签的种类将会有两个以上