




- @m0_74693860
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
评估自编码器的方法是重建误差,即输出的那个数字2和原始输入的数字2之间的差别,当然越小越好。举个例子,图片的像素是二维的格状数据,时间序列在等时间上抽取相当于一维的的格状数据,而视频数据可以理解为对应视频帧宽度、高度、时间的三维数据。但有趣的是,GAN的实际表现比我们预期的要好,而且所需的参数也远远按照正常方法训练神经网络,可以更加有效率的学到数据的分布。举个最简单的例子,我们预测股票走势用RNN
在OpenCV中,计算机视觉算法和机器学习之间有着密切的关系,因为机器学习技术在计算机视觉中发挥了重要作用。传统的计算机视觉算法可能使用SVM(支持向量机)或其他分类器来实现目标检测和图像分类,但随着深度学习的发展,使用卷积神经网络(CNN)等机器学习算法在这些任务上取得了更好的性能。传统的计算机视觉算法中,特征提取通常是手工设计的,如边缘、角点等。综上所述,计算机视觉算法和机器学习在OpenCV

改革开放40年,基础教育研究与实践的最大成就之一,就是树立了“学生是教育主体”的观念。但是,在课堂教学中,学生并未真正成为主体,大多数课堂教学也没有发生根本变化。为什么?因为大多数教学改革尚未抓住教学的根本,对课堂教学的研究还只停留在文本上、观念上,没有落到实际行动中。开展深度学习的研究与实践正是把握教学本质的一种积极努力,是我国课程教学改革走向深入的必需。当前,智能机器尤其是智能化穿戴设备的大量

第一部分主要从 3 个方面来介绍深度学习,包括:深度学习的简介、为什么“深度”、深度学习的“Hello World”。这部分主要讲解了深度学习的很多基本知识点和深度学习训练过程,同时介绍了知名的深度学习框架 Keras, 最后使用 Keras 进行 MNIST 手写数字识别。这部分主要介绍了深度学习未来的发展趋势,包括监督式学习中的超深度网络、注意力模型,强化学习和非监督式学习在图像、文字、音频等

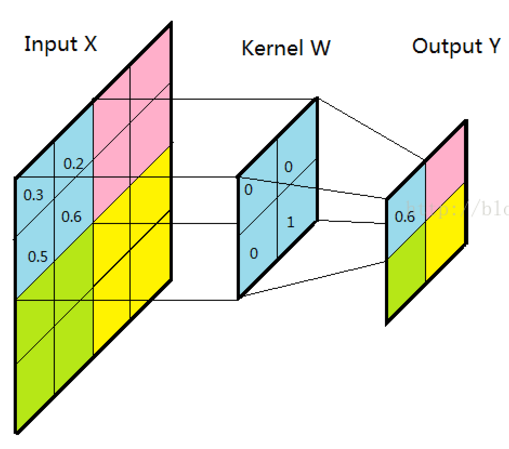
相当于如果我要在一张照片中进行人脸定位,但是CNN不知道什么是人脸,我就告诉它:人脸上有三个特征,眼睛鼻子嘴巴是什么样,再告诉它这三个长啥样,只要CNN去搜索整张图,找到了这三个特征在的地方就定位到了人脸。它就记住了X的长相。上面说到,卷积后产生的特征图中的值,越靠近1表示与该特征越关联,越靠近-1表示越不关联,而我们进行特征提取时,为了使得数据更少,操作更方便,就直接舍弃掉那些不相关联的数据。取
深度学习在计算机视觉领域中的应用越来越广泛,OpenCV也支持深度学习模型的使用。在这个阶段,你可以学习如何使用OpenCV来加载和使用预训练的深度学习模型,例如CNN、RNN、YOLO、SSD等等。此外,你还可以学习如何使用一些深度学习库,如TensorFlow和PyTorch,来训练自己的深度学习模型。此外,你还将学习如何使用卡尔曼滤波器来跟踪目标,并了解更高级的技术,如深度学习目标检测模型。

深度学习是机器学习中一种强大的技术,它模拟人脑神经网络的工作方式,通过构建深层次的神经网络来实现对数据的学习和分析。本文将介绍深度学习的基本原理和概念,帮助读者了解深度学习的工作原理。
在OpenCV中,计算机视觉算法和机器学习之间有着密切的关系,因为机器学习技术在计算机视觉中发挥了重要作用。传统的计算机视觉算法可能使用SVM(支持向量机)或其他分类器来实现目标检测和图像分类,但随着深度学习的发展,使用卷积神经网络(CNN)等机器学习算法在这些任务上取得了更好的性能。传统的计算机视觉算法中,特征提取通常是手工设计的,如边缘、角点等。综上所述,计算机视觉算法和机器学习在OpenCV
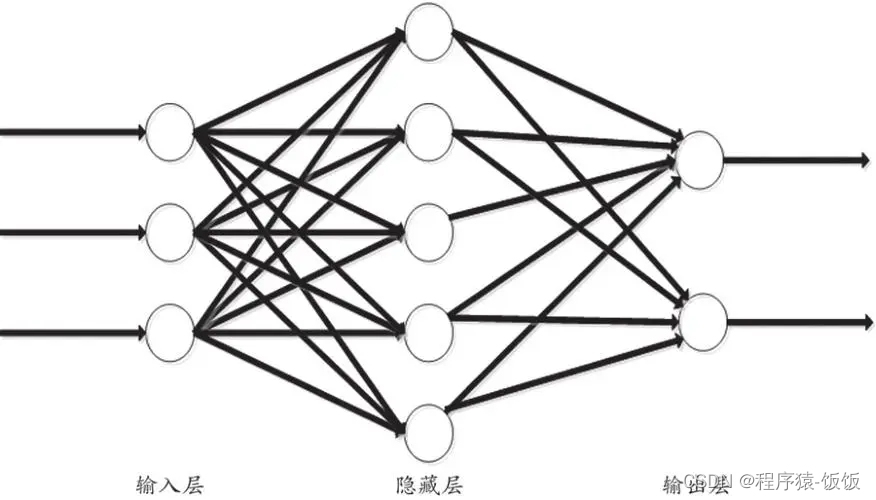
通过反复的前向传播和误差反向传播过程,BP神经网络逐步优化模型的权重和偏置,使得模型能够更准确地预测和分类输入数据。该网络模型的关键在于通过误差反向传播算法有效地计算每个连接权重的梯度,从而实现对网络参数的更新和调整。:根据梯度和学习率的乘积,调整连接权重和偏置的值,以减小误差。输入层接收原始数据作为输入,隐藏层通过一系列中间处理单元提取和表示数据的特征,输出层产生模型的最终输出结果。:输入数据通
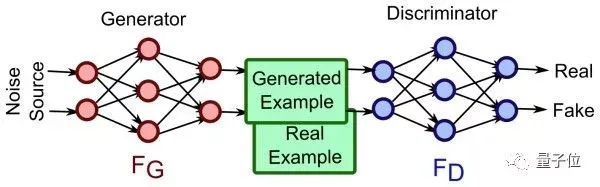
生成对抗网络(Generative Adversarial Network,GAN):生成对抗网络由生成器和判别器组成,通过对抗训练的方式生成逼真的数据样本,被广泛应用于图像生成和数据增强等领域。长短时记忆网络(Long Short-Term Memory,LSTM):LSTM是一种特殊的循环神经网络,通过引入门控机制来解决传统RNN中的梯度消失和梯度爆炸问题,适用于处理长序列数据。此外,可以参考
