




- @m0_73916791
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文不讲解LSTM的理论基础,提供了一个简单的代码实现供参考1.4f一开始比较疑惑为什么cpu版本比gpu版本还快,发现是batch_size设的太小了的原因导致gpu并行计算的能力没有完全体现.4f。
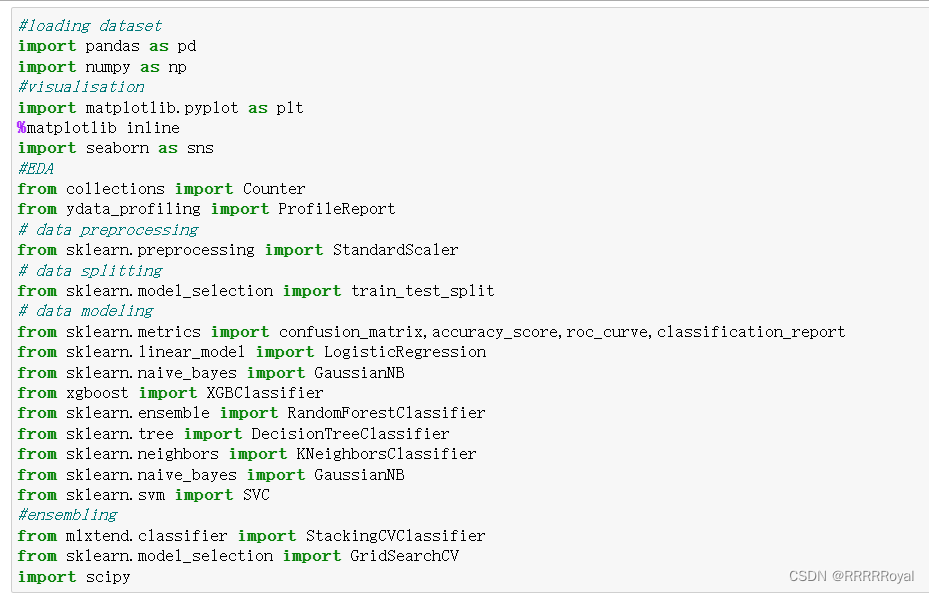
目录:数据集来源算法介绍集成学习模型评估代码实战总结
扩散模型的概念最早起源于统计物理学中的玻尔兹曼机(Boltzmann Machines),这是一类基于能量函数的概率模型,通过初始状态进行蒙特卡洛采样,不断更新样本的状态,以逼近目标分布。例如,深度强化学习中的价值函数蒙特卡洛树搜索(Value Function Monte Carlo Tree Search,VF-MCTS)方法中,扩散模型用于预测状态转移的概率分布,从而指导模型的决策过程。需要
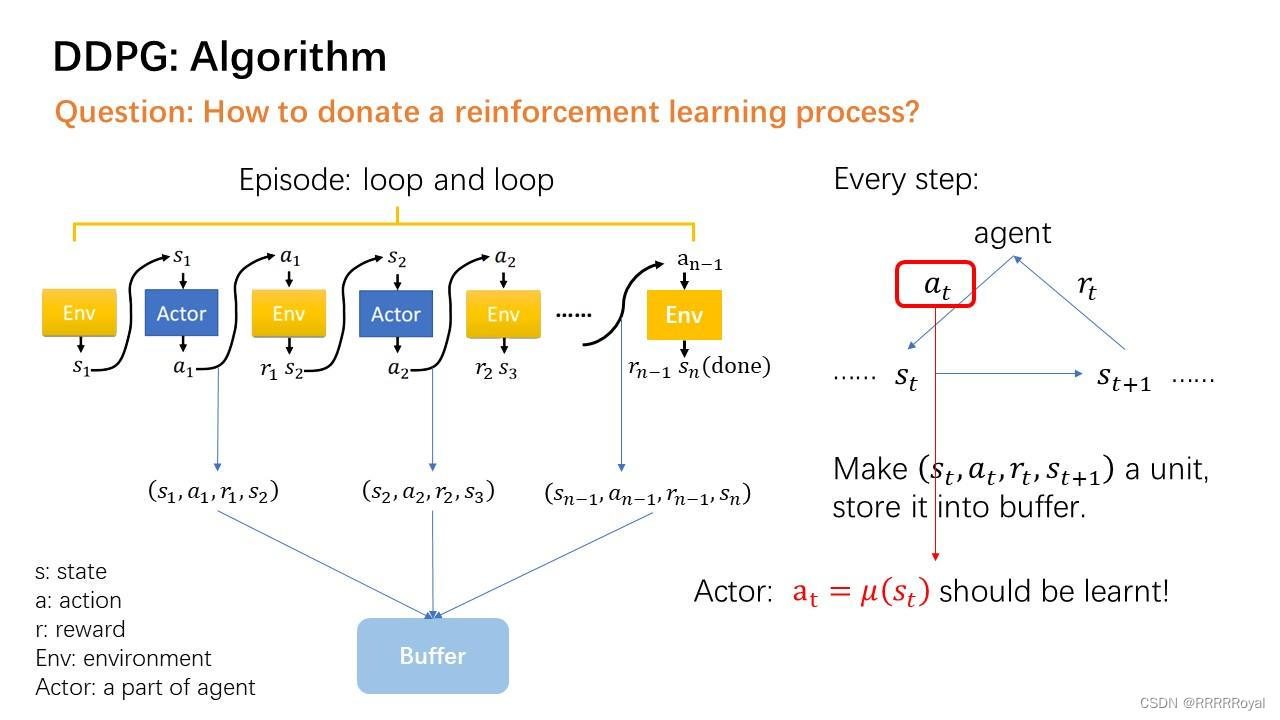
不过,目前有许多开源的强化学习库(如OpenAI Gym、TensorFlow、PyTorch等),提供了DDPG算法的实现示例和教程,可以参考这些库中的示例代码来实现DDPG算法。Actor网络通过最大化值函数Q(s, a)的梯度来更新策略函数的参数,而Critic网络通过值函数的近似来估计最大化累积奖励。其中,Q(s, a)表示在状态s执行动作a的累计奖励估计值,α为学习率,r为当前的立即奖励
在深度学习框架PyTorch中,反向传播算法被封装得非常简洁。PyTorch提供了自动求导机制,这意味着我们不需要手动编写反向传播的代码,框架会自动计算梯度。反向传播是神经网络训练的核心,而PyTorch等现代框架使用自动微分使得实现变得更加容易。但即使使用这些自动化工具,理解反向传播的底层原理也是非常重要的,因为这有助于你更好地理解模型训练的过程,以及如何调试和优化模型。
本文不讲解LSTM的理论基础,提供了一个简单的代码实现供参考1.4f一开始比较疑惑为什么cpu版本比gpu版本还快,发现是batch_size设的太小了的原因导致gpu并行计算的能力没有完全体现.4f。
下面是一个用PyTorch简单实现的前馈神经网络代码示例。输入层有2个节点,含一个隐藏层包含3个节点,输出层有1个节点。1这段代码定义了一个非常简单的前馈神经网络,其有一个含3个神经元的隐藏层,并使用ReLU作为激活函数。模型的训练数据是随机生成的,所以这个网络的实际应用价值不大,但足以作为一个示例来展示如何使用PyTorch开发前馈神经网络。
例如,在上面的代码中,逻辑是假设输入的图像大小是28x28像素,经过两次2x2的池化后,其大小变为7x7像素(原大小除以池化窗口stride的大小的平方),因此在全连接层fc1中的输入特征数量必须设置为64(第二个卷积层的输出通道数)乘以7乘以7(池化后的图像大小)。例如,如果您处理的是更高分辨率的图像,您可能需要更多的卷积层或者更大的全连接层。全连接神经网络是理解复杂网络结构的基础。全连接层通常
扩散模型的概念最早起源于统计物理学中的玻尔兹曼机(Boltzmann Machines),这是一类基于能量函数的概率模型,通过初始状态进行蒙特卡洛采样,不断更新样本的状态,以逼近目标分布。例如,深度强化学习中的价值函数蒙特卡洛树搜索(Value Function Monte Carlo Tree Search,VF-MCTS)方法中,扩散模型用于预测状态转移的概率分布,从而指导模型的决策过程。需要
扩散模型的概念最早起源于统计物理学中的玻尔兹曼机(Boltzmann Machines),这是一类基于能量函数的概率模型,通过初始状态进行蒙特卡洛采样,不断更新样本的状态,以逼近目标分布。例如,深度强化学习中的价值函数蒙特卡洛树搜索(Value Function Monte Carlo Tree Search,VF-MCTS)方法中,扩散模型用于预测状态转移的概率分布,从而指导模型的决策过程。需要