- @m0_73122726
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
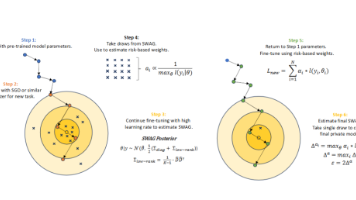
贝叶斯方法与机器学习的融合成为AI研究热点,在模型不确定性量化、联邦学习优化等领域取得突破性进展。MIT团队利用Transformer提升贝叶斯运算效率百倍,武汉科大研发的DaringFed架构提升联邦学习性能16.99%。同时,差分隐私研究提出SWAG-PPM新机制,通过参数平滑而非噪声添加实现隐私保护,在不平衡数据上优于传统方法。此外,针对序数结果的动态治疗策略研究提出OBART模型,结合贝叶
UNet与Transformer的融合模型正成为医学影像、遥感分割等领域的研究热点。UNet擅长局部特征提取但长程建模不足,Transformer能捕捉全局依赖但计算成本高,二者互补形成高效架构。

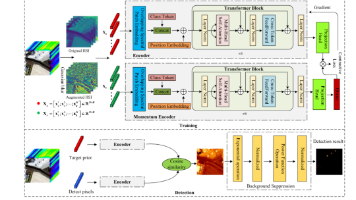
Transformer在目标检测领域取得突破性进展,多篇研究提出创新方法:1)TransDet结合Transformer全局特征捕捉能力,解决小目标检测难题;2)高光谱目标检测研究中,无监督动量对比学习+Transformer编码器显著提升检测性能;3)GSTUnet网络融合全局语义与边缘信息,优化红外小目标检测。这些方法通过创新架构设计(如门控模块、对比学习)和特征融合策略,在复杂场景下实现更高
此外,Transformer拥有强大的全局上下文建模能力和并行计算能力,能精准捕捉图像中的信息,显著提高目标检测的效率。本文提出了一种基于RT-DETR的改进模型RT-DETRv3,通过引入CNN辅助分支和自注意力扰动策略,提供了层次密集正监督,显著提升了模型的训练效果和性能。该方法通过逐步扩展模型表示能力,实现稳定性和可塑性的平衡,并通过分离监督和计算减少类间混淆,进一步提出风险平衡的部分校准以

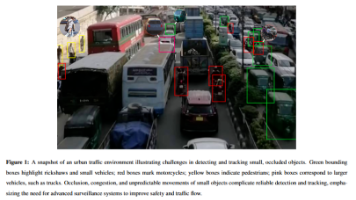
本文探讨了如何通过修改YOLOv5的结构元素及其连接参数,以提高其对小目标(即输入图像中占据较小像素区域的对象)的检测性能,并提出了一系列名为。该框架能够动态更新图结构以适应复杂的交通场景,并通过Grad-CAM等技术增强模型可解释性,实验结果表明其性能显著优于现有方法。针对无人机边缘设备检测进行了优化,通过自适应空间融合机制、动态稀疏注意力和网络剪枝策略,显著提升了小目标检测的精度和效率。则专注
YOLO目标检测技术取得新突破,通过架构改进有效解决小目标检测等难题。YOLO-Drone模型引入GhostHead结构,在无人机图像检测中性能超越主流YOLO版本;YOLO-DS框架提出双统计协同算子,在MS-COCO基准上AP提升1.1%-1.7%。这些创新既保持了YOLO的实时性优势,又显著提高了检测精度,为工业质检、无人机检测等应用提供了更优解决方案。

针对时序预测中传统LSTM模型调参困难、缺乏不确定性量化的问题,近期研究提出贝叶斯优化与LSTM的融合架构。在黄金价格预测中,该模型误差降低33.2%;航空故障预警可提前7天检测,减少35%停机时间。研究采用CEEMD分解、差分处理和贝叶斯优化超参数策略,形成分解-处理-优化框架,验证了其在交通流量(RMSE 0.336)和股票趋势预测(准确率97.41%)中的优越性。贝叶斯LSTM通过自动调参和
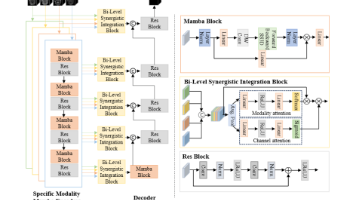
多模态医学图像分割研究取得新突破,有效解决传统方法中特征冗余和模态信息丢失问题。最新研究通过跨模态特征融合和动态注意力机制,显著提升病灶检出率和分割精度:肺癌早筛中CT与PET融合使检出率提高28%,边界误差缩小至0.8mm;脑肿瘤MRI多序列分割准确率提升19%。创新方法采用Mamba架构结合注意力机制,实现高效长程特征提取和多模态自适应融合。半监督学习框架通过多阶段融合和对比互学习,增强跨模态
最近,引起了广泛关注,这是一种创新的频率感知特征融合方法,可以提升数据处理的准确性和效率,尤其在语义分割、目标检测、实例分割和全景分割等任务中表现卓越。通过结合频域分析与特征融合技术,FreqFusion能够捕捉传统时域分析难以揭示的频率特性,展现出深远的研究价值。在现代数据分析和信号处理领域,频域特征融合技术越来越受到重视。这种融合方式不仅能够为我们提供了更深入的数据洞察和决策支持。为了让大家更

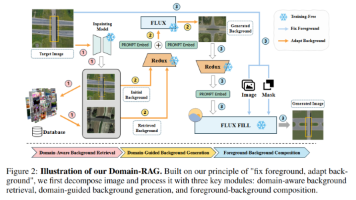
论文提出创新方法解决少样本目标检测难题。Domain-RAG提出首个跨域少样本检测框架,通过检索引导组合图像生成,实现背景域对齐合成,在1-shot场景下无需训练即提升检测性能。TemporalObject-AwareViT将视觉语言模型适配于视频检测,通过选择性传播高置信度目标特征,在5-shot设置下AP提升最高达5.3%。两项工作分别从跨域图像生成和时序建模角度突破数据稀缺瓶颈,在工业质检和