




- @m0_70647377
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
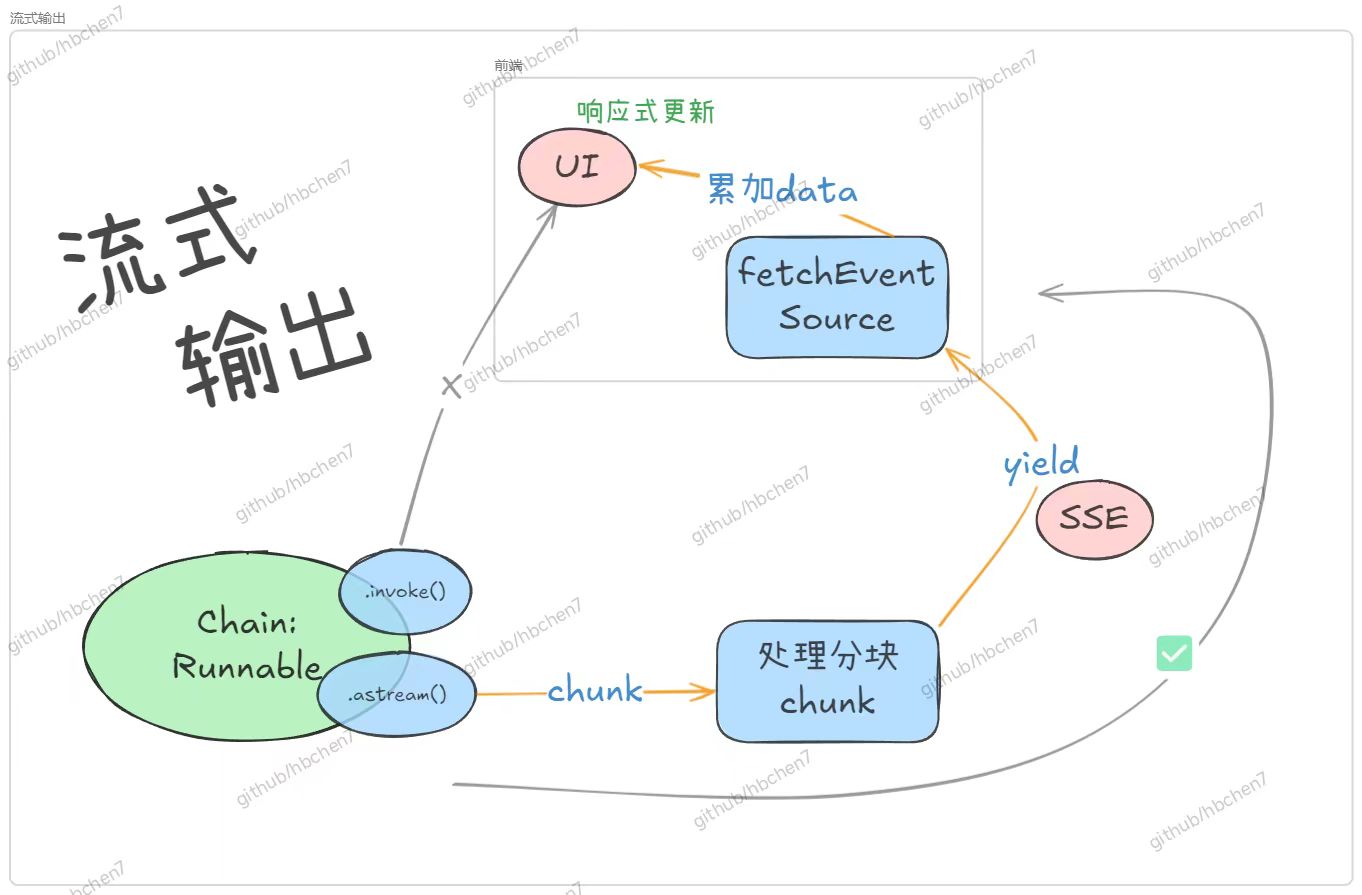
来看这条简单清晰的逻辑链:LLMs_chain.astream(langchain中chain的API:流式输出LLM的一个个回复块「原料chat_sew.stream_chat (生成器,转换chunk为初步的SSE格式字典「初步加工产品)stream_response_generator(生成器,转换SSE协议字符串丨打包成快递)StreamingResponse(FastAPI用于流式传输响
在Dockerfile的最后我们会用到CMD来指定**当Docker容器运行起来以后要执行的命令**。大家需要注意这里容器和镜像的区别,并且它和我们之前讲到的RUN不一样:**RUN是创建镜像时候使用的,而CMD是运行容器的时候使用的。**
来看这条简单清晰的逻辑链:LLMs_chain.astream(langchain中chain的API:流式输出LLM的一个个回复块「原料chat_sew.stream_chat (生成器,转换chunk为初步的SSE格式字典「初步加工产品)stream_response_generator(生成器,转换SSE协议字符串丨打包成快递)StreamingResponse(FastAPI用于流式传输响
第一步:set OLLAMA_HOST=0.0.0.0第二步:ollama serve502问题解决。
self.start = time.time() # 记录开始时间class Timer : def __enter__(self) : self . start = time . time() # 记录开始时间 return self def __exit__(self , * args) : print(f"Elapsed: {time . time() - self . start } se

这是因为`RecursiveCharacterTextSplitter` 的局限性,它将原本相关的文本切成了两个部分,第一个部分被召回,而第二个部分因为包含的信息更少,其向量相关性也下降了,没有被召回。这就导致了检索质量不理想,因为`RecursiveCharacterTextSplitter`既影响了**语块完整性**,也影响了语块的**向量相关性**。
来看这条简单清晰的逻辑链:LLMs_chain.astream(langchain中chain的API:流式输出LLM的一个个回复块「原料chat_sew.stream_chat (生成器,转换chunk为初步的SSE格式字典「初步加工产品)stream_response_generator(生成器,转换SSE协议字符串丨打包成快递)StreamingResponse(FastAPI用于流式传输响
在Dockerfile的最后我们会用到CMD来指定**当Docker容器运行起来以后要执行的命令**。大家需要注意这里容器和镜像的区别,并且它和我们之前讲到的RUN不一样:**RUN是创建镜像时候使用的,而CMD是运行容器的时候使用的。**
至此我们就完成了一个自己的 MCP 客户端了### 好了,现在你可以在简历上写上:精通 MCP 了 [doge]

把 cloud code 里面的模型换成其他的优质的开源模型试试。跑出来的效果依然非常能打,正是因为它本身的工具体系搭的非常的好。
