




- @m0_70466650
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Docker Desktop与Dify集成方案 Docker Desktop是官方容器开发工具,提供Docker Engine、CLI和GUI管理界面。Dify则是开源LLM应用开发平台,支持多模型集成和可视化工作流编排。 使用Docker部署Dify的优势: 简化部署流程,一键启动所有组件 实现环境隔离与一致性 提供可视化管理界面 支持跨平台运行 搭建步骤: 安装Docker Desktop并配

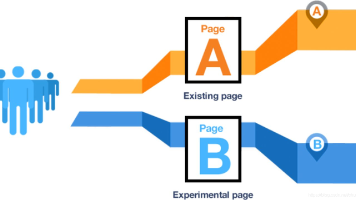
某电商公司希望通过A/B测试验证新版落地页能否将转化率从13%提升至15%。实验采用双尾检验,设计10天周期,每组需至少1万用户样本。通过随机分组比较新旧页面转化率,并监控辅助指标如跳出率。使用Z检验分析数据显著性,若p值<0.05则判定新页面效果显著。技术实现包括数据清洗、样本抽样和统计检验,最终根据结果决定是否全量推广新页面。
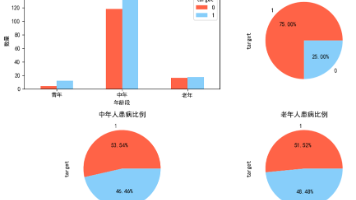
本研究基于Kaggle的Heart Disease数据集(303个样本,14个变量),分析心脏病的影响因素。数据显示:样本中患病率54.5%,女性患病率(75%)显著高于男性(44.9%);年龄分析表明,老年组患病率最高(62.5%),中年(53.3%)和青年组(42.9%)依次降低,证实年龄与患病风险正相关。此外,心率分析显示年龄增长与心率存在关联。研究结论提示性别、年龄和心率是心脏病的重要预测
本文基于链家网站数据,对广州二手房市场进行深入分析。研究采用Python爬取31,626条房源信息,通过数据清洗与可视化发现:广州各区房价差异显著,天河区均价最高(60,131元/㎡),从化区最低(13,199元/㎡);3室2厅户型占比最高(27.79%),符合主流家庭需求;词云分析显示购房者最关注采光和方正等房屋特征。研究还识别出珠江新城中等高价地段,为购房决策提供数据支持,揭示了广州二手房市场

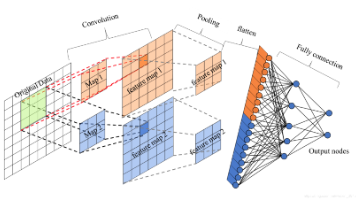
本项目基于Fashion-MNIST数据集构建CNN图像分类模型,通过数据增强、标准化和自定义数据集划分(训练70%、验证15%、测试15%)优化数据处理流程。模型采用"卷积+池化"双模块结构进行特征提取,结合Dropout层防止过拟合。实验结果表明,该CNN架构能有效识别10类衣物图像,测试准确率达91.5%,验证集准确率92.3%,具备良好的泛化能力。关键创新点包括自定义C
本文包含对pytorch的简单介绍,对为什么要使用gpu跑任务以及cuda是什么这个问题进行解释,同时对如何安装pytorch以及创建相应的虚拟环境进行演示,旨在帮助如何去启用gpu跑pytorch的深度学习任务。
异常值是一种沉默的“杀手”,在你去除缺失值准备开始建模的时候,可能会导致你的模型效果不理想或者是十分糟糕,而又不清楚问题出现在哪,所以对于异常值的处理也是非常重要的,本文将讲解什么是异常值以及异常值的处理。异常值有很多,这里所介绍的是关于数值型的异常值,也可以称为“离散值”。异常值是指在数据集中与其他观测值明显不同的数据点或样本。它们可能是由于测量错误、数据损坏、数据录入错误、系统故障或真实的极端
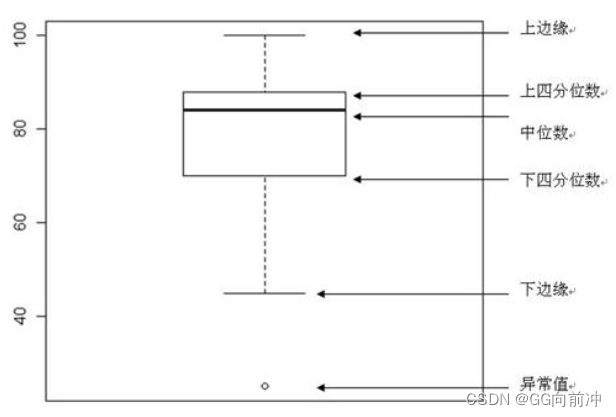
一般所收集到的数据都需要进行数据标准化,因为在数据集中存在许多量纲不同的指标,比如在学生体质数据集中,包含身高(cm)、体重(kg)等身体指标,可以发现两组指标的数据量纲不一致,指标之间的性质、量纲、数量级、可用性等特征均存在差异,这就会导致我们无法直接用其分析研究对象的特征和规律,同时对模型的可靠性也会造成影响。其次数据标准化在深度学习中会被经常使用,其能够减少噪声的同时,加速模型收敛,提高模型

本文包含对pytorch的简单介绍,对为什么要使用gpu跑任务以及cuda是什么这个问题进行解释,同时对如何安装pytorch以及创建相应的虚拟环境进行演示,旨在帮助如何去启用gpu跑pytorch的深度学习任务。
本项目基于Fashion-MNIST数据集构建CNN图像分类模型,通过数据增强、标准化和自定义数据集划分(训练70%、验证15%、测试15%)优化数据处理流程。模型采用"卷积+池化"双模块结构进行特征提取,结合Dropout层防止过拟合。实验结果表明,该CNN架构能有效识别10类衣物图像,测试准确率达91.5%,验证集准确率92.3%,具备良好的泛化能力。关键创新点包括自定义C