- @m0_62464865
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
使用git命令,将主分支的代码同步到子分支上

在日常的工作中经常需要在k8s集群中部署应用,并创建service,步骤虽然简单,但是缺经常忘记,因此总结了下具体的过程,以ngnix为例子。

向k8s集群中添加节点,有时候会遇到各种问题,因此总结了下步骤。

ubuntu server 20.04安装Nvidia显卡驱动,以A6000为例
【代码】ubuntu20.04离线安装Nvidia-container-toolkit。
Redhat上源码安装python3版本。

正则表达式主要用于字符串的模式匹配,或者是字符的匹配。正则表达式还可以将一些非结构化的文档内容转化为结构化。另外一个作用是去除噪声,可以将无关的文本内容去除掉。

基于规则的分词,主要是通过维护词典,在切分语句时,将语句的每个字符串与词表中的词逐一匹配,找到则切分,否则不切分。以上主要总结了三种规则匹配方法,正向最大匹配法,逆向最大匹配法,和双向最大匹配算法,并给出了相应的代码实现,以上代码都可以直接运行出结果。

多模态融合是将不同模态信息(如图像、文本)进行联合建模的技术,核心挑战在于处理异质数据的时空对齐和语义关联。融合方法按阶段分为早期(输入层拼接)、晚期(决策层合并)和中间融合(主流方法)。现代技术主要包括:基于注意力的跨模态交互(如BLIP)、门控机制动态加权(如MFHM)、张量积建模二阶关系(如MUTAN)、轻量适配器注入(如LLaVA)以及生成式隐式融合(如Flamingo)。当前趋势是通过冻

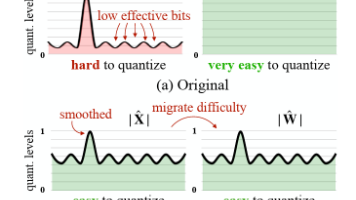
SmoothQuant是一种高效的LLM量化方法,通过数学变换将激活值中的异常值影响迁移到权重上,实现INT8量化。核心思想是引入平滑因子s,对输入激活和权重进行等价变换:Y = (X·diag(s)^{-1})·(diag(s)·W)。平滑因子根据通道最大值和迁移强度α计算,平衡量化难度。该方法可离线完成,无运行时开销,适用于Transformer各层。实验表明,SmoothQuant能在保持模