




- @m0_57280180
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍了在Windows系统下配置Claude Code使用Agent Teams的完整教程。主要内容包括:1) 安装Git for Windows和tmux for Windows的必要步骤;2) 配置settings.json文件启用Agent Teams功能;3) 详细说明tmux在Windows下的工作原理和使用方法;4) 常见问题解决方案。教程强调必须在Git Bash环境下运行,并提
作者是前亚马逊、迪士尼资深工程师使用claude code的经验,干货满满,推荐阅读原文以下是自己的一个阅读心得,分享给大家。

将原始数据集进行筛选,分裂成子数据集(每次分几份,以什么条件分)对生成的子数据集不断分裂,直到停止(停止的条件是什么)利用最终生成的n份数据的共性来代表这个节点(如何用节点共性代表未来预测值?总结,决策树的生成说白了就是数据不断分裂的递归过程,每一次分裂,尽可能让类别一样的数据在树的一遍,当树的叶子节点的数据都是一类的时候,则停止分裂。基尼系数是国际上通用的、用来衡量一个国家或地区收入差距的常用指

在数据处理过程中,会碰到维度爆炸,维度灾难的情况,为了得到更精简更有价值的信息,我们需要进一步处理,用的方法就是降维。降维有两种方式:特征抽取、特征选择过滤式(打分机制):过滤,指的是通过某个阈值进行过滤,比如经常会看到但可能并不会去用的,根据方差、信息增益、互信息、相关系数、卡方检验、F检验来选择特征。(什么是互信息?在某个特定类别出现频率高,但其他类别出现频率比较低的词条与该类的互信息比较大。

作者是前亚马逊、迪士尼资深工程师使用claude code的经验,干货满满,推荐阅读原文以下是自己的一个阅读心得,分享给大家。
本文介绍了在Windows系统下配置Claude Code使用Agent Teams的完整教程。主要内容包括:1) 安装Git for Windows和tmux for Windows的必要步骤;2) 配置settings.json文件启用Agent Teams功能;3) 详细说明tmux在Windows下的工作原理和使用方法;4) 常见问题解决方案。教程强调必须在Git Bash环境下运行,并提
GBDT与传统的Boosting区别较大,它的每一次计算都是为了减少上一次的残差,而为了消除残差,我们可以在残差减小的梯度方向上建立模型,所以说,在GradientBoost中,每个新的模型的建立是为了使得之前的模型的残差往梯度下降 的方向,与传统的Boosting中关注正确错误的样本加权有这很大的区别在GrandientBoosting算法中,关键就是利用损失函数的负梯度方向在当前模型的值作为残

Apache Flink 是一款,以其和而闻名。它能高效地处理(批处理)和(流处理)数据流,是构建实时数仓、在线机器学习、复杂事件处理等应用的基石。下面我将梳理 Flink 的核心概念、关键特性、典型应用场景及学习路径。
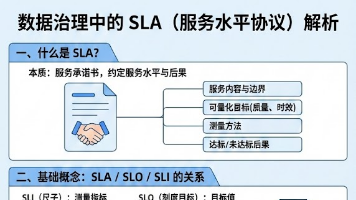
本文探讨了数据治理中的服务水平协议(SLA)及其应用。SLA是服务提供方与接受方关于服务水平的正式约定,包含服务内容、量化目标、测量方法和责任条款。在数据治理中,SLA用于确保数据质量、时效性和可用性,明确各方责任。 文章详细介绍了SLA的核心要素,包括服务指标(SLI)、目标值(SLO)和协议内容(SLA),并阐述了数据治理中常见的SLA类型:数据平台级、数据产品级、数据质量级和治理流程级。同时
本文介绍了使用Docker部署Hadoop和Flink集群的详细过程。作者基于CentOS镜像构建了包含SSH、JDK和Hadoop的基础镜像,创建了三台容器组成Hadoop集群。通过自定义Docker网络实现容器间通信,配置SSH免密登录和hosts文件确保节点互联。文章详细说明了Hadoop核心配置文件的修改方法,包括core-site.xml、hdfs-site.xml等,并强调了版本兼容性
