




- @m0_57167241
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
了解我的朋友应该都知道,我之前一直负责的是云原生网络相关的工作,对容器化,k8s 基本上属于有一定的知识储备。所以本系列的文章主要是一个云原生从业人员的角度去切入到机器学习和大数据方面,对应有一定k8s知识储备的朋友来说可能比较友好,但是对于一些炼丹师朋友来说可能是一个全新的角度,如果需要一些云原生的基础知识的话,也可以看我云原生基础的专栏。
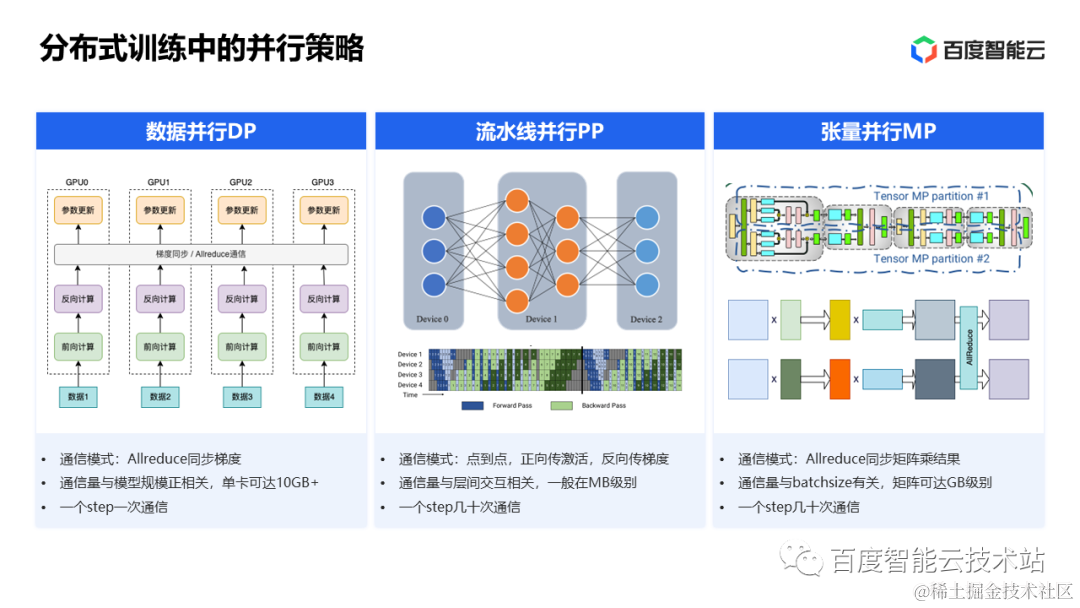
前言,云原生网络的基础就是在主机层面的网络虚拟化而来,将原有的网络空间通过虚拟化隔离出单独的网络空间。在宿主机中的每个容器获得一个单独的网络空间,对网络资源的隔离就是云原生网络的基础。所以本文主要是对云原生的基石linux 网络虚拟化相关的知识相关笔记。
目前我遇到的大规模集群,基本上都是像dd 这样选择晚上的窗口期升级的,这点倒是没什么可说的,但是很少有直接原地升级的,基本上都是有备份升级的,流量也不会直接全部涌入升级后的集群的,要经过逐步验证才会切换到新集群的,原地升级我只能说是艺高人胆大了。但是当企业剩下的大部分都是ppt高手,真正干活的人黯然退场。从dd 的技术博文上能猜出来,原地升级的方案肯定是经过他们内部验证了,最起码短期内是没出问题,
了解k8s 容器网络的小伙伴肯定经常可以看到underlay 网络和bgp 相关的字眼,比如cilium calico 等等cni 都支持了bgp 协议,但是什么是bgp 和为什么要用到bgp 不太清楚,本文会从什么是bgp ,以及为什么要用到bgp 来揭开它的神秘面纱在了解BGP 之前我们需要了解一些背景知识。

如何从零开始部署一套自己的K8S 集群
目前的部署方式,我们通过service 的cluster ip 来做副本的服务发现,还需要对多个job 分别编写配置文件,有许多的重复工作,如果是ps 架构,配置想可能更麻烦,所以我们需要一个在k8s集群上统一的作业发布平台,来代替我们配置一些重复工作。
了解我的朋友应该都知道,我之前一直负责的是云原生网络相关的工作,对容器化,k8s 基本上属于有一定的知识储备。所以本系列的文章主要是一个云原生从业人员的角度去切入到机器学习和大数据方面,对应有一定k8s知识储备的朋友来说可能比较友好,但是对于一些炼丹师朋友来说可能是一个全新的角度,如果需要一些云原生的基础知识的话,也可以看我云原生基础的专栏。