




- @m0_55834564
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
解决方案:http://t.csdn.cn/yBu9Z输入命令service iptables stop,就可以访问了就能打开端口连接不上mysql也用这个方法
本文详细介绍在 Ubuntu 22.04 LTS 系统上从零开始安装、配置、部署 OpenClaw AI 助手框架的完整流程,包含环境准备、安装步骤、服务配置、故障排查等内容。
本文详细介绍在 Ubuntu 22.04 LTS 系统上从零开始安装、配置、部署 OpenClaw AI 助手框架的完整流程,包含环境准备、安装步骤、服务配置、故障排查等内容。
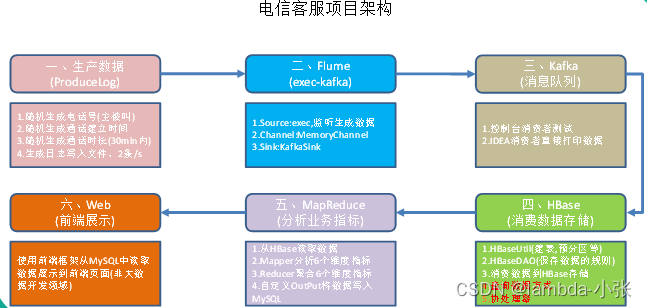
数据量如此巨大,除了要满足用户的实时查询和展示之外,还需要定时定期的对已有数据进行离线的分析处理。例如,当日话单,月度话单,季度话单,年度话单,通话详情,通话记录等等+。此情此景,对于该模块的业务,即数据生产过程,一般并不会让你来进行操作,数据生产是一套完整且严密的体系,这样可以保证数据的鲁棒性。但是如果涉及到项目的一体化方案的设计(数据的产生、存储、分析、展示),则必须清楚每一个环节是如何处理的
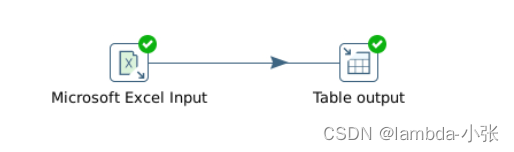
通过“表输入”对MySQL表格的数据读入,然后通过“JavaScript代码”更新抽取数据的时间,再通过“表输入出”保存表格到MySQL数据库。1.利用Kettle的“表输入”,“表输入出”,”JavaScript代码”组件,实现数据全量更新。2.熟练掌握“JavaScript代码”,“表输入”,“表输入出”组件的使用,实现数据全量更新。Step3:配置‘字段’选项卡,获取字段名称,并设置字段的数
目录1.请谈一下hive的特点?2.Hive底层与数据库存交互原理?3.Hive内部表和外部表的区别?4.Hive导入数据的五种方式是什么?举例说明5.hive与传统关系型数据库的区别6.Hive中创建表有哪几种方式,其区别是什么?7.Hive的窗口函数有哪些8.row_number(),rank()和dense_rank()的区别9.Hive如何实现分区10.Hive的两张表关联,使用MapRe
版本介绍Centos6.5下Hadoop伪分布式安装虚拟机软件:Parallels Desktop10Hadoop各节点节点操作系统:CentOS 6.5JDK版本:jdk1.8.0HBase版本:hbase-1.4.13下载地址:http://archive.apache.org/dist/hbase/二、第一步:安装软件...
目录1.hbase建表2.创建数据3.导入依赖4.写map和job5.输出结果6.虚拟机查询1.hbase建表hbase(main):002:0> create 'emp','info'0 row(s) in 1.7460 seconds=> Hbase::Table - emp2.创建数据[root@hadoop dool]# vim emp.txt1201,gopal,manage
实现效果如下:代码如下:(有一些bug未能解决)<!DOCTYPE html><html lang="zh"><head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><meta http-equ
1.修改zoo_sample.cfg名称。3.配置zoo.cfg。