




- @m0_55196097
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
要使用 Jupyter Notebook 绘制一个神经网络的结构图,可以使用 `torchsummary` 库中的 `summary` 函数。该函数可以显示模型的结构以及每一层的输出形状等信息。

错误内容就在类型不匹配,根据报错内容可以看出Input type为torch.cuda.FloatTensor(GPU数据类型),而weight type(即网络权重参数这些)为。复现程序时想要拿出项目代码中数据处理(dataloader)得到的数据,然后在jupyter notebook上将该数据应用于特征提取网络。既然输入数据是GPU类型,那解决方法就是将网络权重参数类型转变为GPU类型。.F
这两个函数对于模型微调(fine-tuning)和迁移学习(transfer learning)等场景非常有用。例如,在迁移学习中,你可能希望冻结预训练模型的一部分参数,只更新模型的最后几层以适应新任务。通过这两个函数,可以方便地控制模型参数的梯度计算状态。这段代码定义了两个函数:`freeze_net` 和 `unfreeze_net`,这两个函数的目的是分别冻结和解冻一个神经网络模型的参数,控
这两个函数对于模型微调(fine-tuning)和迁移学习(transfer learning)等场景非常有用。例如,在迁移学习中,你可能希望冻结预训练模型的一部分参数,只更新模型的最后几层以适应新任务。通过这两个函数,可以方便地控制模型参数的梯度计算状态。这段代码定义了两个函数:`freeze_net` 和 `unfreeze_net`,这两个函数的目的是分别冻结和解冻一个神经网络模型的参数,控
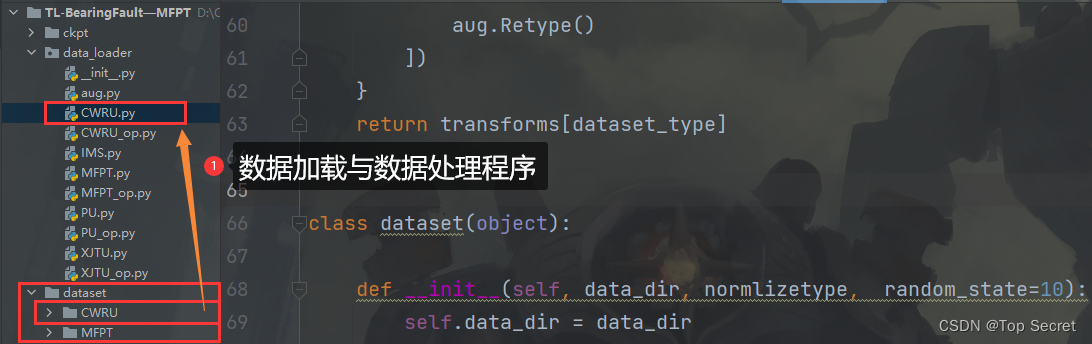
若想改变原来写“一体化”代码的习惯,养成将代码分块,其实就是python中模块化的思想。),导入数据,设置好一些超参数。(2)然后再根据数据预处理的基本步骤,将各个步骤写成函数,于数据集类中。(4)编写好模型训练代码(train.py)。主要在于导入包部分,其他的训练代码的写法其实和“一体化”代码一样。导入如上(1)(3)中的数据和模型,所以在train.py中。需要导入这两个模块。
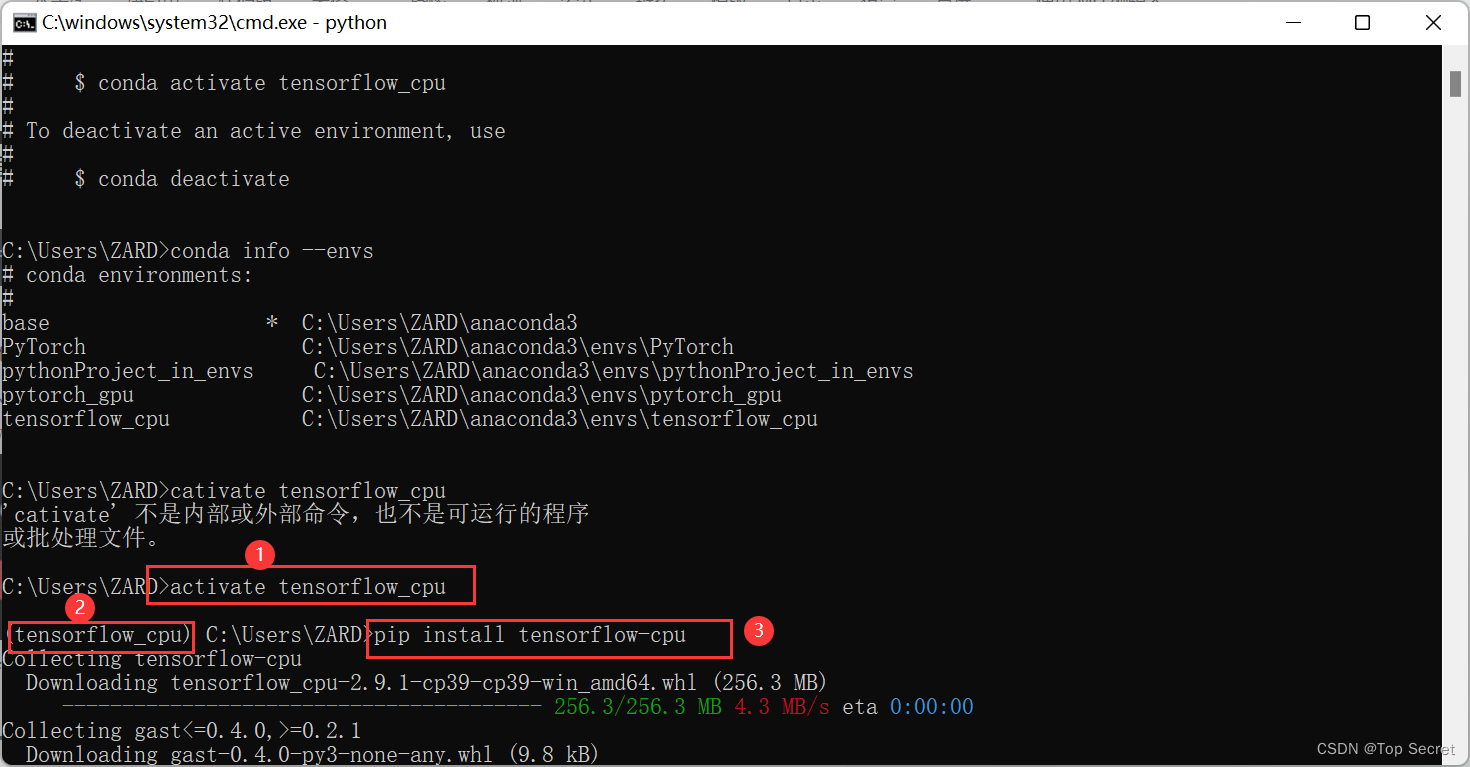
习惯使用PyCharm来开发,而 Anaconda 集成了python开发环境,因此我们可以修改Project的python编译环境,从而更方便使用tensorflow框架。File-Setting–Project Interpreter选择tensorflow下的Python解释器。最后 完美的安装了最新的tensorflow 2.4.1 cpu版本。等需要使用GPU版的tensorflow再继
这些模型通常是基于神经网络的,其目标是最小化嵌入向量之间的距离,使得具有相似上下文的词被嵌入到相近的位置。嵌入矩阵中每一行对应于一个单词的向量表示,可以将这些向量用于不同的自然语言处理任务,例如语言模型、文本分类和命名实体识别等。训练嵌入模型:使用准备好的训练数据,对嵌入模型进行训练,通常使用随机梯度下降等优化算法来最小化模型的损失函数。需要注意的是,嵌入矩阵的维度和嵌入模型的超参数(例如窗口大小
它包括采用预先训练的模型(在源任务上训练的模型),并使用它来改进新目标任务的学习。这可以包括使用模型作为特征提取器,微调模型,或使用模型的部分作为初始化。
开头的为单元命令,单元命令则必须出现在单元的第一行(而且不能有注释),对整个单元的代码进行处理。%%script :写bash、perl、javascript、js 等命令。: 加载指定路径下的python文件代码到当前单元格。%%writefile:将当前cell中内容写入文件中。: 测试单行代码单次执行的时间,并返回测试结果;开头的为行命令,行命令只对命令所在的行有效;: 显示当前命名空间中定

开头的为单元命令,单元命令则必须出现在单元的第一行(而且不能有注释),对整个单元的代码进行处理。%%script :写bash、perl、javascript、js 等命令。: 加载指定路径下的python文件代码到当前单元格。%%writefile:将当前cell中内容写入文件中。: 测试单行代码单次执行的时间,并返回测试结果;开头的为行命令,行命令只对命令所在的行有效;: 显示当前命名空间中定