- @lirendada
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在 .proto枚举类型名称:使用驼峰命名法,首字母大写。例如: MyEnum枚举内常量值名称:全大写字母,多个字母之间用 _连接。例如: ENUM_CONST = 0;我们可以定义一个名为 PhoneType// 移动电话// 固定电话0值常量必须存在,且要作为第一个元素。(这是为了与proto2的语义兼容)若在使用枚举类型的时候没有赋值,则默认使用 0值常量,即0值常量就是默认值!枚举类型可
Redis 介绍基本概念与特点:内存数据库、高性能、键值存储。数据结构支持:String、Hash、List、Set、SortedSet 等。应用场景:缓存、会话管理、排行榜、消息队列。Jedis 客户端。Jedis 简介:Java 客户端库的定位与核心功能。基础使用示例:连接池配置、基本命令操作(SET/GET)事务与 Pipeline:批量操作与性能优化Spring Data Redis框架整
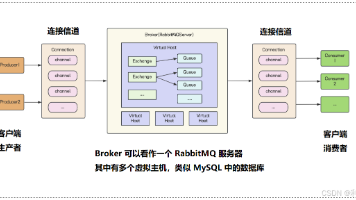
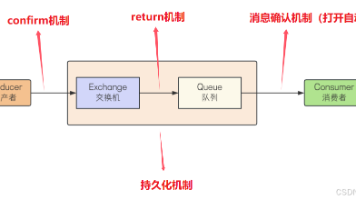
本文介绍了RabbitMQ的核心概念和工作流程。RabbitMQ是一个基于生产者-消费者模型的消息中间件,负责接收、存储和转发消息。核心概念包括Producer(生产者)、Consumer(消费者)、Broker(RabbitMQ服务器)、Connection(TCP连接)、Channel(虚拟通道)、Virtualhost(虚拟主机)、Queue(消息队列)和Exchange(消息交换机)。消息
本文介绍了RabbitMQ的消息确认机制,包括自动确认和手动确认两种模式。自动确认(autoAck=true)适用于可靠性要求不高的场景,消息发送后立即删除;手动确认(autoAck=false)则需消费者显式调用Basic.Ack命令,确保消息可靠处理。文章详细说明了三种确认方式:肯定确认(basicAck)、否定确认(basicReject)和批量否定确认(basicNack),并分析了Spr
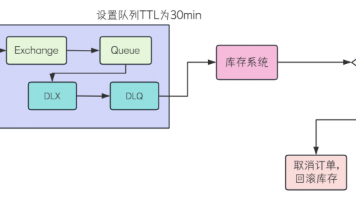
RabbitMQ提供了重试机制和TTL(消息过期)功能来优化消息处理。重试机制分为自动确认和手动确认两种模式:自动模式下Spring捕获异常自动重试,需配置重试次数和间隔;手动模式下需自行实现重试逻辑,但可能导致消息积压。TTL可设置队列级(所有消息统一过期)或消息级(单条消息独立过期),以较小值为准。典型应用场景包括订单超时自动取消等。使用时需注意自动确认模式可能导致消息丢失,而手动确认可能引发
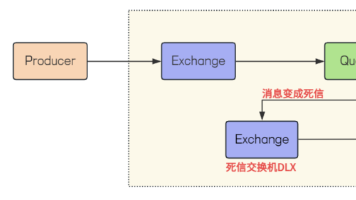
本文介绍了RabbitMQ延迟队列的实现方式。延迟队列适用于需要在特定时间后处理消息的场景,如智能家居定时控制、会议提醒等。RabbitMQ原生不支持延迟队列,但可通过TTL+死信队列组合实现:设置消息过期时间后自动转入死信队列,消费者监听死信队列获取延迟消息。不过这种方式存在队首消息阻塞问题,不同延迟时间需要单独队列。更优方案是使用RabbitMQ官方延迟插件,通过声明延迟交换机实现精确延迟控制
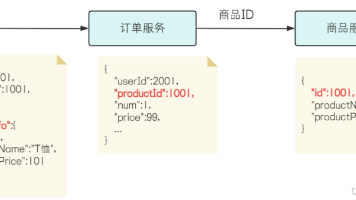
本文介绍了Spring Cloud微服务开发的环境搭建和项目拆分原则。开发环境要求JDK17和MySQL 5.7/8.0,并详细说明了电商平台微服务拆分的三大原则:单一职责、服务自治和单向依赖。通过订单服务和商品服务的拆分示例,展示了如何根据业务功能划分微服务,并为每个服务配置独立数据库。最后简要说明了如何构建父子工程来管理微服务项目,包括使用properties统一管理版本号、dependenc
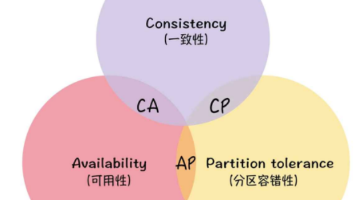
本文介绍了微服务架构中的注册中心概念及其核心作用。注册中心作为服务实例的"地址簿",实现了服务的动态发现,解决了硬编码URL的问题。文章阐述了注册中心的三种角色(服务提供者、消费者、注册中心)和核心功能(服务注册、发现、健康检查),并基于CAP理论对比了Zookeeper、Eureka和Nacos等常见注册中心的特性差异。重点演示了如何搭建Eureka注册中心服务器,以及将服务
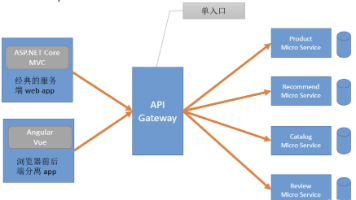
本文介绍了API网关的概念及其在微服务架构中的核心作用。API网关作为后端服务的统一入口,解决了接口直接暴露的安全性问题,并通过路由、鉴权、限流等功能实现流量治理。文章对比了Spring Cloud Gateway、Zuul、Nginx等多种网关实现方案,指出Spring Cloud Gateway是当前Java微服务项目的首选方案。同时详细讲解了Spring Cloud Gateway的快速上手
Spring Cloud Gateway的过滤器分为GatewayFilter和GlobalFilter两种类型。GatewayFilter通过配置文件实现,作用于单个路由或路由组;GlobalFilter通过代码实现,作用于所有路由。GatewayFilter示例展示了如何通过AddRequestParameter为请求添加参数,而default-filters可配置全局生效的过滤器。Globa