




- @lihui49
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
看BaikalDB如何借助模型上下文协议(MCP),让数据库对话像聊天一样简单——无需编写代码,大语言模型即可完成复杂数据分析。

本文作者从信息论出发,用一个简单的框架帮你拆解 AI Coding 里的种种困惑——当你不再跟着新概念焦虑,而是回到"信息"和"不确定性"的底层逻辑,很多问题会清晰得多。所以低熵更像模型的自信度,不等于正确性。真实复杂业务里,大量关键约束属于填补层的问题——兼容逻辑、历史包袱、团队默认的业务边界,这些往往没有被写进任何文档,也没有被编码进任何测试。它们不会直接降低互信息,但会把模型先验 P 往错误

本文主要是盘一盘OpenClaw的基本内容,也是常见使用者涉及到核心点。解决网络教程太分散,官方又太详细使人眼花。01 调整心态、缓解焦虑:评估openclaw对自身的价值,要不要用缓解一下持续话题带来的焦虑02 从了解、到部署、到上手实践:了解基本概念如何安装部署、可能遇到的问题如何切换各类模型供应商常见配置修改和命令使用提供一种有些深度的多Agent实践以及目前存在的开源案例03 一些可以避开

目前已经支持的平台包括:Telegram(Bot 模式)、WhatsApp(Business API)、飞书(机器人)、钉钉(Stream 模式)、微信(个人号扫码登录)、企业微信(机器人)、Slack(Bot)、Discord(Bot)、Google Chat(Bot)、Microsoft Teams(Bot)、百度如流(企业通讯)以及 Gotify(推送)。我在实现 GoClaw 时踩过一个很

是由百度地图开发平台推出并已开源的 App 稳定性分析 Agent。项目已在团队内部推广使用,持续沉淀历史崩溃模式和排查经验,帮助缩短 Crash 排查时间、降低新人上手门槛。我们更看重的是“长期复利”:通过向量数据库驱动的数据飞轮,把一次次线上故障处置转化为可检索、可治理、可继承的稳定性知识资产,让系统越用越聪明、团队越用越省力。项目定位是App 稳定性分析的统一 Agent 框架——闪退(Cr
本文整理自 2022 年 12 月的智算峰会 · 智算技术分论坛上的同名主题分享。
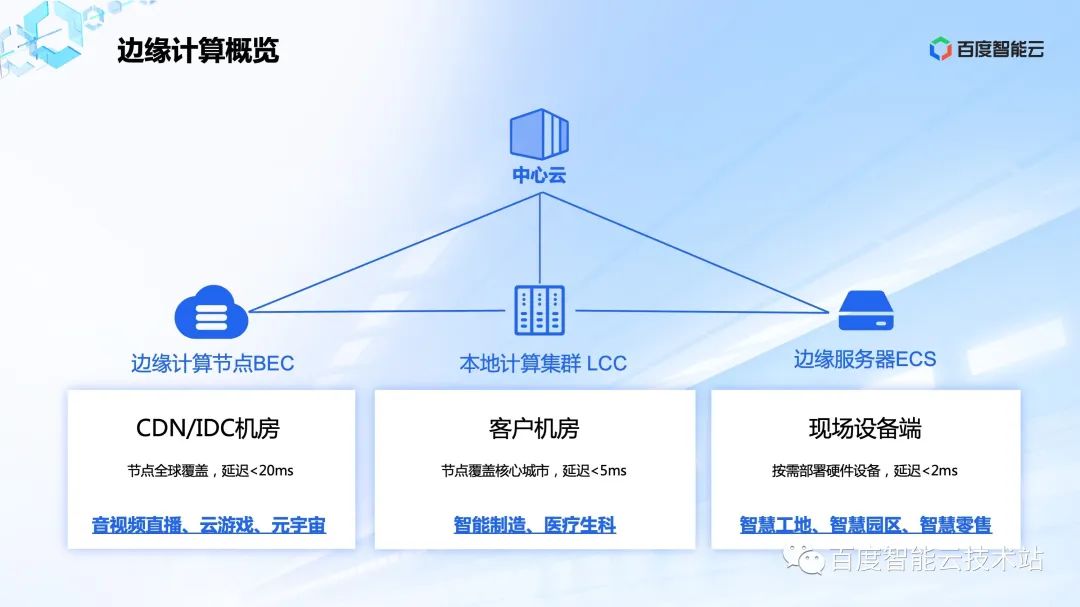
面对复杂的业务场景,百度数据分析平台(TDA) 通过分析能力增强与性能优化双轮驱动,来持续保障用户的分析体验

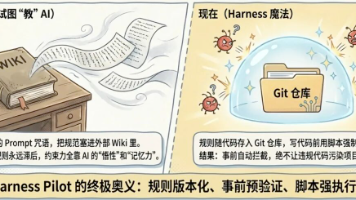
Harness Pilot 作为一款 Claude Code 插件,集成了两大核心 Skill、五类内置 Agent 以及一套分层模板系统。4.1 两个 Skill分析流程包含以下四个步骤:评分权重分配为:文档覆盖率 35%、架构合规度 35%、测试覆盖率 30%,并支持历史趋势追踪。开发模式选择(Development Mode)在初始化和代码生成模式中,首先进行开发模式选择(Step 0),再
每个 MCP 工具通过转换为tools[]格式,命名遵循// toolToAPISchema 核心逻辑return {name: tool.name, // 如 "mcp__github__create_issue"description: await tool.prompt(), // 工具描述 → tools[].descriptioninput_schema: tool.inputJSONS

最近我想给大模型训推任务灵犀诊断平台增加「自我演化」的功能,尝试使用claude code的最新的/goal命令,记录从需求拆解到代码合入的完整流程,供同学参考。最近两周codex、hermes相继发布/goal斜杠命令,这一周 claude code也不甘示弱,跨速发布了它的 /goal 斜杠命令。本文将/goal斜杠命令 + /prd技能 + /after-goal技能,实现了一个产品特性研发
