- @liangdaojun
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
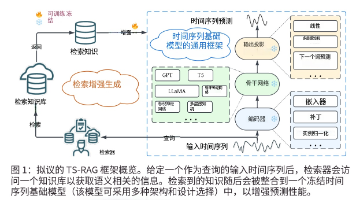
本文提出TS-RAG,一种基于检索增强生成的时间序列预测框架,通过预训练编码器从多领域知识库中检索相似历史模式,并利用自适应检索混合器动态融合检索信息,显著提升了零样本预测性能。实验表明,TS-RAG在7个基准数据集上平均降低3.54% MSE和1.43% MAE,最高提升6.84%,同时推理速度比同类方法快360倍。该框架不仅实现了SOTA性能,还通过检索证据提供了良好的可解释性,为时间序列基础
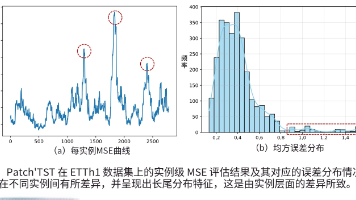
本文提出PIR框架,针对时间序列预测中的实例级变异问题(由分布偏移、缺失数据和长尾模式导致),通过模型无关的事后修正方法提升预测可靠性。PIR包含三个核心组件:基于不确定性估计的故障识别模块、利用局部上下文信息的修正模块和基于相似历史检索的全局修正模块。在12个真实数据集上的实验表明,PIR能平均降低MSE最高达25.87%,尤其对通道独立模型效果显著。该框架无需修改原模型结构,计算开销低,为提升
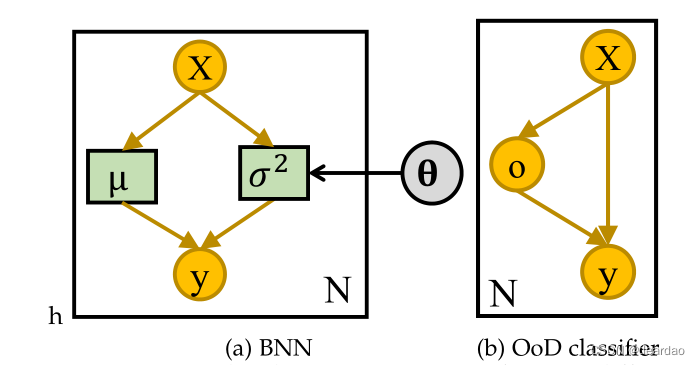
不确定性量化(UQ)在减少优化和决策过程中的不确定性方面起着关键作用,应用于解决各种现实世界的科学和工程应用。贝叶斯近似和集成学习技术是文献中使用最广泛的两种UQ方法。在这方面,研究人员提出了不同的UQ方法,并测试了它们在各种应用中的性能,如计算机视觉(如自动驾驶汽车和物体检测)、图像处理(如图像恢复)、医学图像分析(如医学图像分类和分割)、自然语言处理(如文本分类、社交媒体文本和惯犯风险评分)、
“上帝是一位算术家!”——雅克比深度学习(DeepLearning)是人工神经网络(artificialneuralnetwork)的一个分支。1943年,来自美国的数学家沃尔特·皮茨(W.Pitts)和美国心理学家沃伦·麦克洛克(W.McCulloch)首次提出人工神经网络的概念,并对其中的神经元进行了数学建模,从此人工神经网络这一研究领域被开启[1]。194...
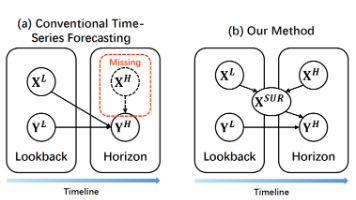
论文摘要(149字) ICLR 2026论文《Tackling Time-Series Forecasting Generalization via Mitigating Concept Drift》针对时间序列预测中的概念漂移被忽视问题,提出模型无关框架ShifTS:通过软注意力掩码(SAM)提取外生特征不变模式缓解概念漂移,结合RevIN归一化处理时间偏移。实验显示,ShifTS在6个数据集上
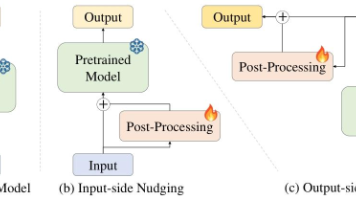
我们提出了一种事后轻量化、与架构无关的方法,无需重新训练即可提升已部署的时间序列预测模型性能。
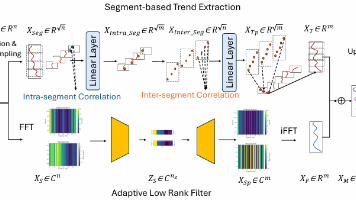
MixLinear是ICLR 2026提出的极低资源多元长时序预测模型,仅含0.1K参数。该模型创新性地采用时域分段趋势提取与频域自适应低秩谱滤波的双路径架构,将时序建模复杂度从O(n²)降至O(n)。在8个标准数据集上,MixLinear实现了与Transformer/线性SOTA模型相当的预测精度,最高优化16.2%的MSE指标,同时获得3.2倍推理加速和81%参数量缩减。模型核心优势在于:1
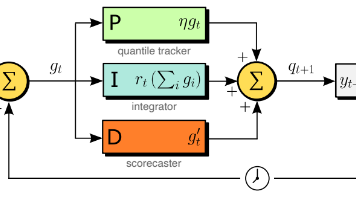
本文聚焦大语言模型(LLM)时间序列预测中开环自回归推理引发的误差累积(暴露偏差)与长视界轨迹漂移问题,从控制理论视角提出F-LLM(Feedback-driven LLM)闭环预测框架
不确定性量化(UQ)在减少优化和决策过程中的不确定性方面起着关键作用,应用于解决各种现实世界的科学和工程应用。贝叶斯近似和集成学习技术是文献中使用最广泛的两种UQ方法。在这方面,研究人员提出了不同的UQ方法,并测试了它们在各种应用中的性能,如计算机视觉(如自动驾驶汽车和物体检测)、图像处理(如图像恢复)、医学图像分析(如医学图像分类和分割)、自然语言处理(如文本分类、社交媒体文本和惯犯风险评分)、
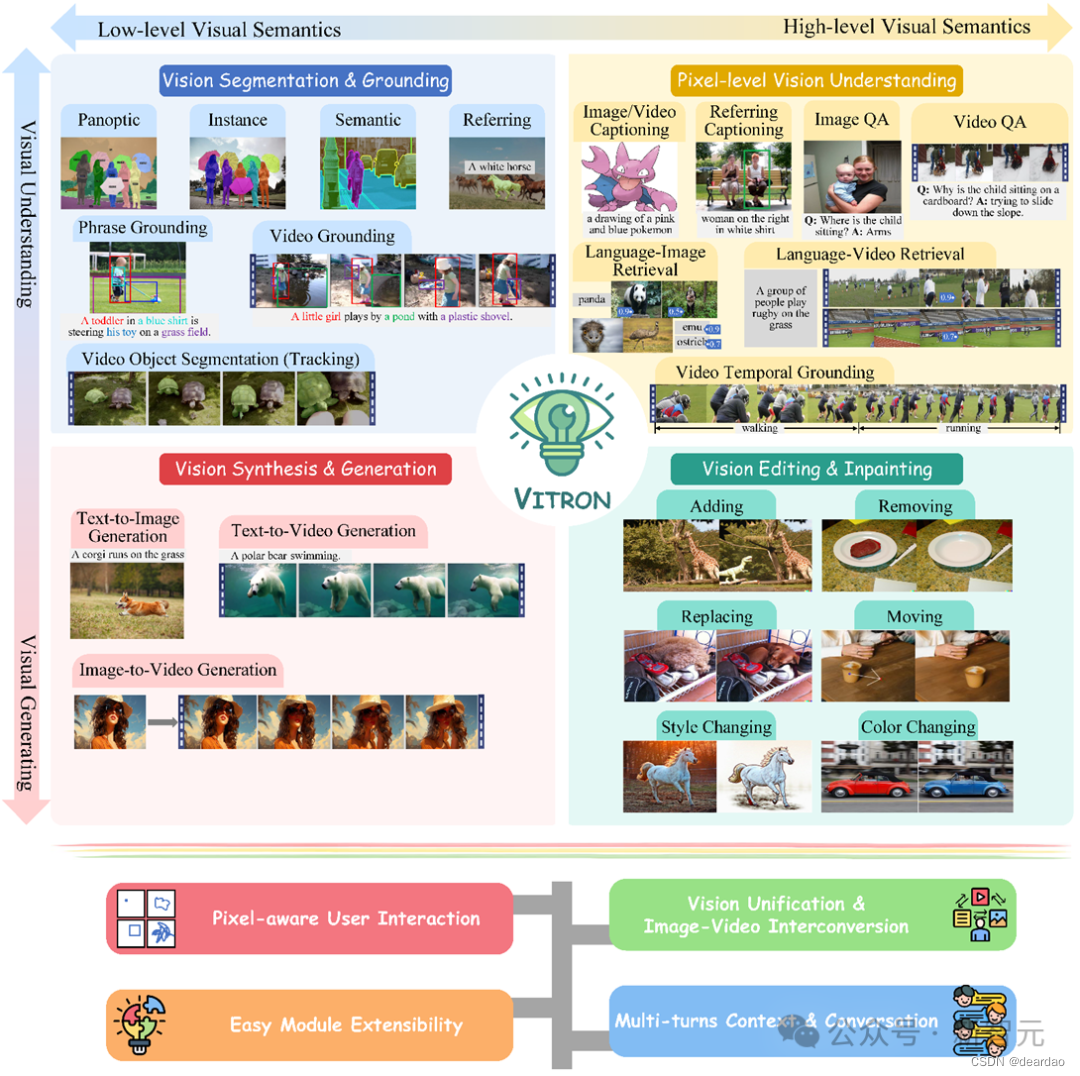
一方面,研究人员尝试深化MLLMs对视觉的理解,从粗略的实例级理解过渡到对图像的像素级细粒度理解,从而实现视觉区域定位(Regional Grounding)能力,如GLaMM、PixelLM、NExT-Chat和MiniGPT-v2等。部分研究已经开始研究让MLLMs不仅理解输入视觉信号,还能支持生成输出视觉内容。Vitron作为一个统一的像素级视觉多模态大语言模型,实现了从低层次到高层次的视觉