




- @ldlno
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
为了满足实验课对人机对话系统的设计要求,我们在现有Chat对话模型的基础上进行了功能扩展。当前系统已实现基于文本输入的人机交互功能,现计划通过以下技术升级优化用户体验:首先,集成语音识别(STT)模型,将用户的语音提问实时转换为文本;然后将识别结果输入预训练的聊天大模型进行处理;最后通过语音合成(TTS)技术将模型的文本回复转换为自然语音输出。这种端到端的语音交互方案能够显著提升人机对话的自然度和
这是一个全程运行在你本地的 AI 对话系统。基于阿里巴巴 Qwen3 系列模型深度构建。语音识别(ASR):采用 Qwen3-ASR 1.7B,精准识别外部输入。智能对话(LLM):通过 Ollama 驱动 Qwen3 4B,本地大脑快速响应。语音合成(TTS):结合 Qwen3-TTS,赋予 AI 自然的人类声线。系统底层由 Rust 语言编写,确保了音频流采集的超低延迟。无论是免驱麦克风还是内
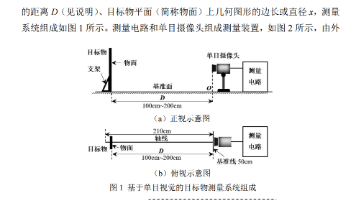
2025TI杯全国大学生电子设计竞赛上海赛区C题参考代码基于K230开发板实现,包含五个主要Python文件:main.py作为入口文件连接五个按钮控制程序执行,分别对应不同图形检测模式(model1检测正方形、model2检测圆形、model3检测三角形、model4为拓展题代码、model5整合三种图形检测)。代码采用自适应阈值处理和距离计算算法,通过图像处理识别A4纸外框并计算目标距离(D值
这是一个全程运行在你本地的 AI 对话系统。基于阿里巴巴 Qwen3 系列模型深度构建。语音识别(ASR):采用 Qwen3-ASR 1.7B,精准识别外部输入。智能对话(LLM):通过 Ollama 驱动 Qwen3 4B,本地大脑快速响应。语音合成(TTS):结合 Qwen3-TTS,赋予 AI 自然的人类声线。系统底层由 Rust 语言编写,确保了音频流采集的超低延迟。无论是免驱麦克风还是内
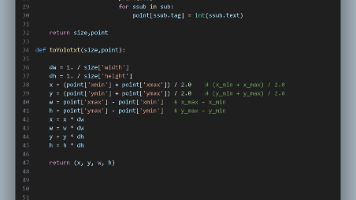
本文介绍了将XML格式的目标检测数据集转换为YOLO格式的方法及代码实现。XML数据集通常包含目标类别和边界框信息,而YOLO格式则包括类别标签序号、归一化后的中心坐标(X_Center, Y_Center)以及宽度(Width)和高度(Height)。通过提供的代码,用户可以高效地将XML格式的数据集转换为YOLO所需的格式,从而方便在YOLO框架中进行目标检测任务。这一转换过程对于使用YOLO
为了满足实验课对人机对话系统的设计要求,我们在现有Chat对话模型的基础上进行了功能扩展。当前系统已实现基于文本输入的人机交互功能,现计划通过以下技术升级优化用户体验:首先,集成语音识别(STT)模型,将用户的语音提问实时转换为文本;然后将识别结果输入预训练的聊天大模型进行处理;最后通过语音合成(TTS)技术将模型的文本回复转换为自然语音输出。这种端到端的语音交互方案能够显著提升人机对话的自然度和
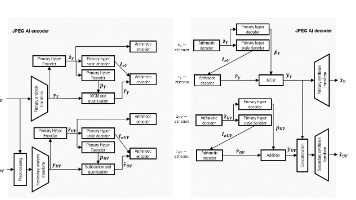
JPEG AI是一种基于学习的图像编码新标准,融合变分自编码器技术,在压缩效率和重建质量上超越传统VVC标准。其核心特点包括:1)单码流支持多分辨率解码;2)采用YCbCr色彩空间和多种子采样方案;3)通过多分支解码框架实现设备兼容性;4)创新性地结合主/次分量处理流程,包含分析变换、超先验编解码和多阶段上下文建模。该标准特别优化了CPU部署效率,支持4K图像在190ms内解码,同时具备色域编码、
比如在自己的环境变量里配置好OLLAMA模型的端口。本文的目的在于快速搭建一个前端Ai对话模型,模型基于已有的LLM模型和自己构建的知识库回答用户问题。部署Dify需要先安装好docker ,安装docker的教程可以参考其他博主,这一步比较简单不再赘述。如下先添加chat模型:之后也需要添加Text Embedding模型 不然在解析自己的文本知识库的时候会非常的慢。也可以使用阿里的通义千问模型
vue+springboot+tts+stt搭建人机对话网页应用
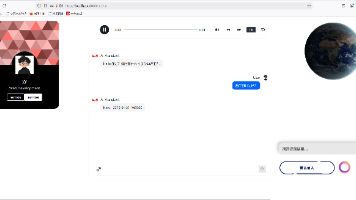
为了满足实验课对人机对话系统的设计要求,我们在现有Chat对话模型的基础上进行了功能扩展。当前系统已实现基于文本输入的人机交互功能,现计划通过以下技术升级优化用户体验:首先,集成语音识别(STT)模型,将用户的语音提问实时转换为文本;然后将识别结果输入预训练的聊天大模型进行处理;最后通过语音合成(TTS)技术将模型的文本回复转换为自然语音输出。这种端到端的语音交互方案能够显著提升人机对话的自然度和