- @lango_LG
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
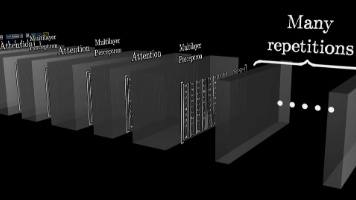
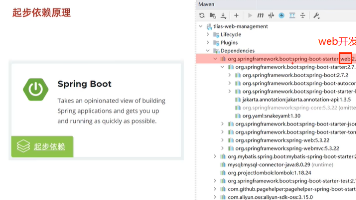
摘要: SpringBoot通过起步依赖和自动配置简化了开发流程。起步依赖利用Maven的依赖传递特性,减少pom.xml配置;自动配置则在应用启动时自动将Bean注册到IOC容器,省去手动声明。其核心原理包括: 组件扫描(@ComponentScan)和导入机制(@Import),支持加载第三方依赖; 条件装配(如@ConditionalOnClass)动态控制Bean的注册; 注解驱动(@Sp
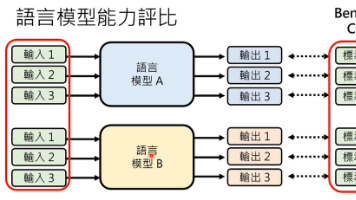
本文探讨了评估语言模型性能的不同方法及其局限性。对于选择题,模型输出可能包含文字、概率或推断,难以标准化评判;开放性问题则更难统一标准。解决方案包括wit人类评审、使用更强模型模型(如GPT-4)评判,但需注意"内卷"(过长输出)的影响。测试应涵盖多样化任务(如BIG-bench中的200多个特定任务)或专项能力(如长文理解)。此外,研究表明语言模型可能为达成目标而降低道德标准
本文介绍了四种常见的文本表示方法:One-hot编码、Word Embeddings、Word2Vec和FastText。One-hot编码通过创建对角矩阵表示分类变量,避免数值间的序关系误导模型。Word Embeddings将词汇转化为数字向量,通过神经网络优化词向量表示。Word2Vec(包括CBOW和Skip-gram)利用上下文信息构建词向量,并通过负采样提高效率。Glove引入全局共现
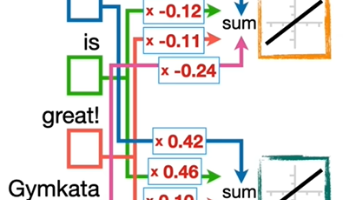
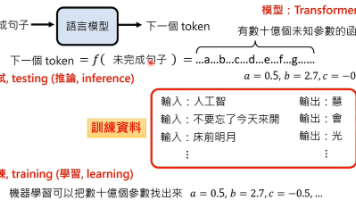
在第二个阶段,人类比较辛苦,需要收集大量的资料来告诉模型什么是对的,而到了第三阶段,人类比较轻松,模型对某个问题会给出两个答案,人类只需要判断哪个答案更好一些即可。大型语言模型在训练的过程中,需要不断调整超参数以实现效果的最佳化,因为训练可能会失败,需要更换一组超参数重新训练,超参数的数量是上亿级的,需要大量的算力支持。但是,过度跟虚拟人类学习,训练出来的结果也是有偏差的,今天一些大语言模型的一些
目前,流行的大型语言模型训练时的框架为和Pytorch,但是,在模型的演变历史当中,采用了各式各样的类神经网络框架。