




- @jsjkyq
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
全球AI算力基建竞争白热化,两大云巨头同步布局Agent基础设施。在WAIC2025上,阿里云推出无影AgentBay,作为专为AIAgent开发的云端超级电脑,提供沙箱环境、多系统支持(含移动端)、数据持久化和企业级安全等核心功能,解决Agent开发中的环境适配与算力需求难题。
Genie 3 是我们突破性的世界模型,可以通过单个文本提示词创建交互式、可玩的环境。从照片般逼真的风景到奇幻的境界,可能性无穷无尽。据介绍,在 Genie 3 生成的动态世界中,玩家可以每秒 24 帧的速度实时导航,模拟自然世界:生成充满活力的生态系统,从动物行为到复杂的植物生命。建模不同地点和历史背景:超越地理和时间的界限,探索各地和历史场景。模拟世界的物理属性:展现自然现象如水与闪电,以及复
港大与快手团队提出ContextasMemory方法,通过将历史视频帧作为记忆条件,实现了长视频生成的场景一致性。该技术创新性地采用基于相机轨迹视场的记忆检索机制,显著提升了计算效率。实验显示其效果接近DeepMind未开源的Genie3,

深度学习领域创新研究新思路:特征提取模块改良成为论文高效产出路径。
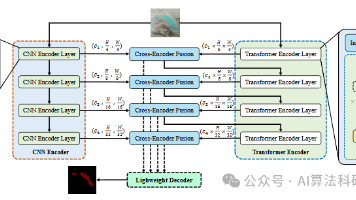
PINN实在太好发论文了!在Nature、Science,和NeurIPS、ICLR等顶会上,都是霸榜的存在。PINN(物理信息神经网络)与LSTM(长短期记忆网络)的融合研究,已成为深度学习领域突破高区的创新路径。
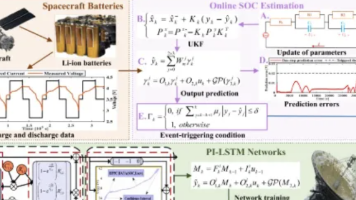
上海交大赵海团队发布全球首个人脑启发大模型BriLLM,突破传统Transformer架构局限。
PINN实在太好发论文了!在Nature、Science,和NeurIPS、ICLR等顶会上,都是霸榜的存在。PINN(物理信息神经网络)与LSTM(长短期记忆网络)的融合研究,已成为深度学习领域突破高区的创新路径。
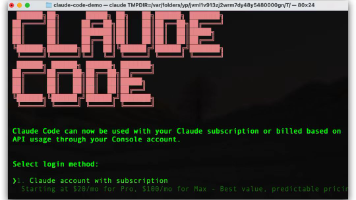
目前最炙手可热的 AI 编程工具非 Claude Code 莫属,它是一个强大的 AI 编程助手,可以让您可以直接在终端中与 AI 协作编程,今天就来介绍下如何玩转Claude code。
Meta开源新一代视觉基础模型DINOv3,在自监督学习领域实现重大突破。该模型通过17亿图像训练和70亿参数规模,在15个视觉任务、60多个基准测试中超越专业解决方案。其创新性的GramAnchoring策略和RoPE编码技术,使模型无需微调即可处理高分辨率图像并生成优质特征图。Meta已开源包括卫星图像专用模型在内的多个版本,该技术已成功应用于医疗影像、环境监测等领域,为计算机视觉研究提供了强
PINN实在太好发论文了!在Nature、Science,和NeurIPS、ICLR等顶会上,都是霸榜的存在。PINN(物理信息神经网络)与LSTM(长短期记忆网络)的融合研究,已成为深度学习领域突破高区的创新路径。