




- @jiaomongjun
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
XGBoost是一种高效的梯度提升决策树(GBDT)实现,广泛应用于机器学习和数据科学领域。它通过组合多个弱学习器(如决策树)来构建强学习器,具有以下核心特点:1)使用二阶导数优化,提升模型精度;2)引入正则化项,防止过拟合;3)支持并行计算,提高训练效率;4)采用后剪枝和稀疏感知算法,增强模型灵活性。XGBoost还通过列块存储、缓存优化和外存计算等技术,进一步优化了大规模数据处理能力。与Lig

通过以上策略和代码示例,可以在千万级数据集上高效完成模型调参。实际应用中建议结合业务特点调整参数范围,并通过自动化流水线实现持续优化。
神经网络(Neural Networks,简称NN)是一类模仿生物神经系统的数学模型,用于处理和解决各种类型的任务,如分类、回归、模式识别等。神经网络属于机器学习领域的一个重要分支,特别是在深度学习(Deep Learning)中起到了核心作用。神经网络通过层次化非线性变换实现强大的函数拟合能力,其成功依赖于:架构设计(如CNN处理图像、Transformer处理文本)。优化技术(如Adam、Dr
线性回归(Linear Regression)是一种用于预测一个连续型目标变量(因变量)与一个或多个自变量(特征变量)之间关系的统计方法。它的基本思想是通过拟合一条直线(在多变量情况下是超平面),来建立自变量和因变量之间的关系模型。
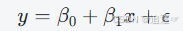
它通过构建多个决策树(Decision Tree),并通过集成学习的思想,最终输出多个决策树的结果的平均值或多数投票结果,从而提高模型的准确性和稳定性。随机森林的核心思想是通过构建多个决策树,并结合它们的结果来进行预测。决策树继续生长,直到满足一定条件(例如,树的深度达到预设的最大值,或者节点的样本数小于某个阈值)为止。随机选择特征:在每个决策树的每个节点,选择一个随机的特征子集来进行分裂,而不是
(Semantic Segmentation)的结合,正在计算机视觉领域发挥越来越重要的作用。语义分割的核心是为图像或视频中的每个像素分配语义类别标签(如“人”“车”“天空”),而大模型的引入显著提升了分割的精度、泛化能力和应用场景。,使其从纯视觉任务升级为感知-推理-决策闭环中的智能组件。未来随着多模态大模型的演进,语义分割将进一步融入通用人工智能(AGI)系统。大模型(如多模态大语言模型、视觉
决策树(Decision Tree)是一种非参数的监督学习算法,适用于分类和回归任务。其核心思想是通过一系列规则(if-then结构)对数据进行递归划分,最终形成一棵树形结构,实现预测或分类。
神经网络(Neural Networks,简称NN)是一类模仿生物神经系统的数学模型,用于处理和解决各种类型的任务,如分类、回归、模式识别等。神经网络属于机器学习领域的一个重要分支,特别是在深度学习(Deep Learning)中起到了核心作用。神经网络通过层次化非线性变换实现强大的函数拟合能力,其成功依赖于:架构设计(如CNN处理图像、Transformer处理文本)。优化技术(如Adam、Dr
神经网络(Neural Networks,简称NN)是一类模仿生物神经系统的数学模型,用于处理和解决各种类型的任务,如分类、回归、模式识别等。神经网络属于机器学习领域的一个重要分支,特别是在深度学习(Deep Learning)中起到了核心作用。神经网络通过层次化非线性变换实现强大的函数拟合能力,其成功依赖于:架构设计(如CNN处理图像、Transformer处理文本)。优化技术(如Adam、Dr
【代码】python解析返回值类型为xml的数据接口。