




- @higerwy
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
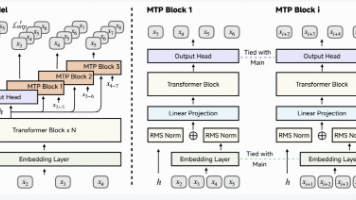
本文介绍了如何利用 SGLang 框架高效部署小米 MiMo-7B-RL 大模型。SGLang 凭借 RadixAttention、Cuda Graph 捕获和 FlashInfer 后端支持,成为新一代推理加速工具。作者详细展示了在 NVIDIA A800-80GB 服务器上的部署流程,包括环境配置、模型下载、服务启动和性能测试。实测显示,SGLang 能快速加载模型(4.4秒加载14.21GB
摘要 本文探讨了BERT模型因参数量大导致计算开销高的问题,提出使用PyTorch动态量化技术进行压缩优化。动态量化通过将模型权重从32位浮点(FP32)转换为8位整型(INT8),显著减少模型体积和推理延迟,尤其适合CPU部署场景。量化过程仅需一行代码,支持Transformer架构的线性层优化,且无需校准数据。实验表明,量化后模型在精度损失可控的情况下,存储和计算效率显著提升,为边缘设备和高并

Docker技术2025年全景解析:本文系统梳理了Docker容器技术的现代实践,涵盖架构原理、构建优化、安全防护和生产部署等关键领域。重点包括:1)轻量级容器架构解析(Namespaces/Cgroups/UnionFS);2)多阶段构建与BuildKit应用(镜像体积缩减87.5%);3)全生命周期安全方案(Rootless模式/SBOM/运行时加固);4)生产级Compose配置与Kuber

本文详细介绍了在Ubuntu/Debian系统上编译安装GPU版LAMMPS的完整流程。重点包括:1) 系统环境准备,包括CUDA和GCC版本兼容性检查;2) 常见问题解决方案,如GCC版本冲突、MPI库缺失和GPU架构检测失败;3) 针对NVIDIA A100显卡的完整编译配置步骤,包括关键CMake参数说明。文章还提供了GPU计算能力查询方法和验证安装的测试命令,为材料科学和分子动力学模拟研究
本文深入解析检索增强生成(RAG)技术栈,涵盖核心原理与工程实践。首先介绍RAG如何通过检索外部知识解决大语言模型的三大局限(知识陈旧、幻觉问题、私有知识盲区),并对比其与微调方案的优劣。重点剖析Embedding模型如何将文本映射为语义张量,以及向量相似度度量方法。随后系统梳理向量数据库的核心价值,对比主流索引算法(IVF、HNSW、PQ等)特性,并详细评测Milvus与FAISS的性能差异。最
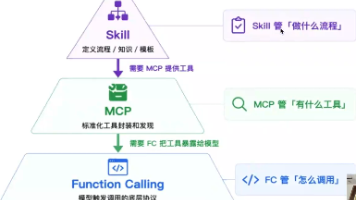
Loop Engineering 的出现是为了解决大模型在复杂工程场景中缺乏系统性、持续性和自我修正能力的问题。它将 AI 的交互模式从被动的“问答式”转变为主动的“代理式”。维度Prompt Engineering (传统)Loop Engineering (新范式)交互模式人工输入提示 -> 模型输出 -> 人工评估再输入设定目标 -> 模型自主循环执行 -> 自动验证 -> 完成执行特征单次

Loop Engineering 的出现是为了解决大模型在复杂工程场景中缺乏系统性、持续性和自我修正能力的问题。它将 AI 的交互模式从被动的“问答式”转变为主动的“代理式”。维度Prompt Engineering (传统)Loop Engineering (新范式)交互模式人工输入提示 -> 模型输出 -> 人工评估再输入设定目标 -> 模型自主循环执行 -> 自动验证 -> 完成执行特征单次
Loop Engineering 的出现是为了解决大模型在复杂工程场景中缺乏系统性、持续性和自我修正能力的问题。它将 AI 的交互模式从被动的“问答式”转变为主动的“代理式”。维度Prompt Engineering (传统)Loop Engineering (新范式)交互模式人工输入提示 -> 模型输出 -> 人工评估再输入设定目标 -> 模型自主循环执行 -> 自动验证 -> 完成执行特征单次
Python绘制动态图
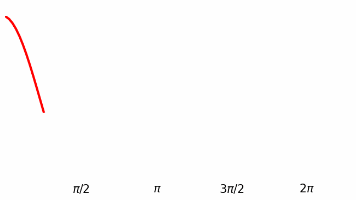
本文提出了一种基于CNN-LSTM-MHA混合模型和灰狼优化算法(GWO)的时序预测方法。该模型通过1D-CNN提取局部特征,双向LSTM建模长期依赖,多头注意力机制聚焦关键时间步,实现了时序数据的多层次建模。创新性地引入GWO算法自动优化超参数,解决了传统调参效率低的问题。实验表明,该方法在保持较高预测精度的同时,显著提升了训练效率。全文提供了完整的PyTorch实现代码,包含混合精度训练、Cu
