




- @fengbeely
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
这次大模型的成功是多个子领域的成功碰撞出的结果,例如模型设计(Transformer)、Data-centric AI(对数据质量的重视)、强化学习(RLHF)、机器学习系统(大规模集群训练)等等,缺一不可。从GPT-1到ChatGPT/GPT-4,所用的训练数据大体经历了以下变化:小数据(小是对于OpenAI而言,对普通研究者来说也不小了)->大一点的高质量数据->更大一点的更高质量数据->高质

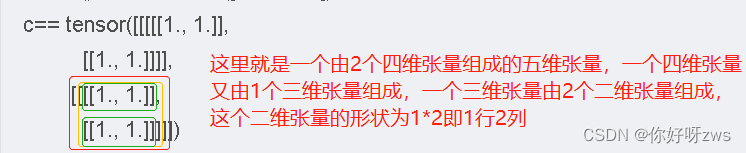
有python编程基础的朋友应该都看过下面这个例子:b=ab[1]=10a由上面的例子中我们不难看出来,python列表中将一个已经存在的列表(a)赋给另一个列表(b)得出列表(b)是和原列表()共用一块内存的,共用即说明这两个列表无论是修改哪一个的元素值,另一个也会随着变化,就比如上面的列表a,b,改变b的值a也会变,同样改变a,b也变,大家可以之行测试一下。
序列化的实现,将需要被序列化的类实现Serializable 接口,该接口没有需要实现的方法,implements Serializable 只是为了标注该对象是可被序列化的,然后使用一个输出流(如:File Output Stream)来构造一个 Object Output Stream(对象流)对象,接着,使用 Object Output Stream 对象的 write Object(Obj

大型语言模型(LLM)是一种人工神经网络,可以从大量文本数据中学习并生成各种主题的自然语言文本。LLM 接受的语料库包含来自不同来源的数十亿或数万亿单词,例如书籍、网站、社交媒体帖子、新闻文章等。LLM 可以执行各种自然语言处理(NLP)任务,例如文本分类、情感分析、问答、机器翻译、文本摘要、文本生成等。流行的 LLM 的一些例子包括 OpenAI 的 ChatGPT、Google 的 Bard、
这次大模型的成功是多个子领域的成功碰撞出的结果,例如模型设计(Transformer)、Data-centric AI(对数据质量的重视)、强化学习(RLHF)、机器学习系统(大规模集群训练)等等,缺一不可。从GPT-1到ChatGPT/GPT-4,所用的训练数据大体经历了以下变化:小数据(小是对于OpenAI而言,对普通研究者来说也不小了)->大一点的高质量数据->更大一点的更高质量数据->高质
这两年,大模型扮演着科技和人工智能领域中的关键角色,在各行各业中都已经如日中天,例如爆火的ChatGPT3.5、GPT4等等。大模型是指在机器学习和深度学习领域中,具有大规模参数和复杂结构的模型。这类模型通常包含大量的神经元和层次结构,使得其能够处理高维度的输入数据,并在训练过程中学习到更为抽象和复杂的特征。深度(Depth): 大模型通常具有深层次的结构,包含多个隐藏层,使其能够从数据中学习到更

(无监督多任务学习器):基于WebText数据集+参数扩至1.5B+无监督语言建模ULM代替明确微调(ULM来解决各种任务+统一视为单词预测问题)+采用概率式的多任务求解(输入和任务信息为条件去预测输出):在8个不同的语言模型相关数据集上测试,有7个实现了SOTA。NLP之GPT-2:GPT-2的简介(大数据/大模型/灵感点)、安装和使用方法、案例应用之详细攻略。

这次大模型的成功是多个子领域的成功碰撞出的结果,例如模型设计(Transformer)、Data-centric AI(对数据质量的重视)、强化学习(RLHF)、机器学习系统(大规模集群训练)等等,缺一不可。从GPT-1到ChatGPT/GPT-4,所用的训练数据大体经历了以下变化:小数据(小是对于OpenAI而言,对普通研究者来说也不小了)->大一点的高质量数据->更大一点的更高质量数据->高质