




- @dundunmm
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
使用特征(如 Petal Length, Petal Width, Sepal Length)绘制三维散点图,观察三类鸢尾花的分布差异。在1936年首次提出,用于展示线性判别分析的应用。鸢尾花数据集因其简单性和易于理解的特性,常被用于教学和研究中。鸢尾花数据集以其简单性和实用性,为数据科学与机器学习的学习和研究提供了重要帮助,是入门不可或缺的经典数据集。鸢尾花数据集(Iris Dataset)是数
Nemenyi检验是Friedman检验的后续分析方法,用于比较多个算法之间的两两差异。Friedman检验只能告诉我们整体上是否存在显著差异,而Nemenyi检验能够进一步确定。Nemenyi检验是基于Friedman检验结果的多重比较方法。它是一种配对比较检验,通常用于多组数据间的成对比较。Nemenyi检验的核心是通过对所有可能的组对进行比较,检查它们之间的差异是否显著。

Prompt,中文一般译为“提示词”或“提示语”,指的是用户向人工智能模型发出的输入内容。这些内容可以是问题、指令、描述性语句、对话背景等,其核心目的是引导 AI 产生有针对性的输出。简而言之,Prompt 就是你对 AI 说的话,是一种“编写语言”的过程。通过优化 Prompt 的表达方式,可以让 AI 模型更准确地理解用户意图,从而生成更加精准和高质量的回答。例如:普通 Prompt:“帮我写


KL 散度是一种衡量两个概率分布相似度的重要工具,在机器学习、深度学习、NLP 和数据压缩等多个领域有广泛应用。它是非对称的,且可以用交叉熵来表示,在变分推断、信息论和深度学习模型优化中至关重要。是衡量两个概率分布 P 和 Q之间差异的一种非对称度量。它用于描述当使用分布 Q 逼近真实分布 P 时,信息丢失的程度。因此,最小化 KL 散度等价于最小化交叉熵。

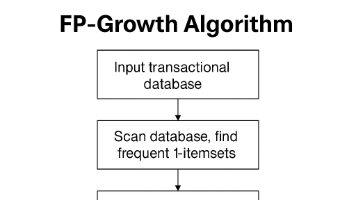
FP-growth(Frequent Pattern Growth)算法是一种高效挖掘频繁项集的算法,它避免了Apriori算法中繁重的候选集生成和多次数据库扫描的问题。
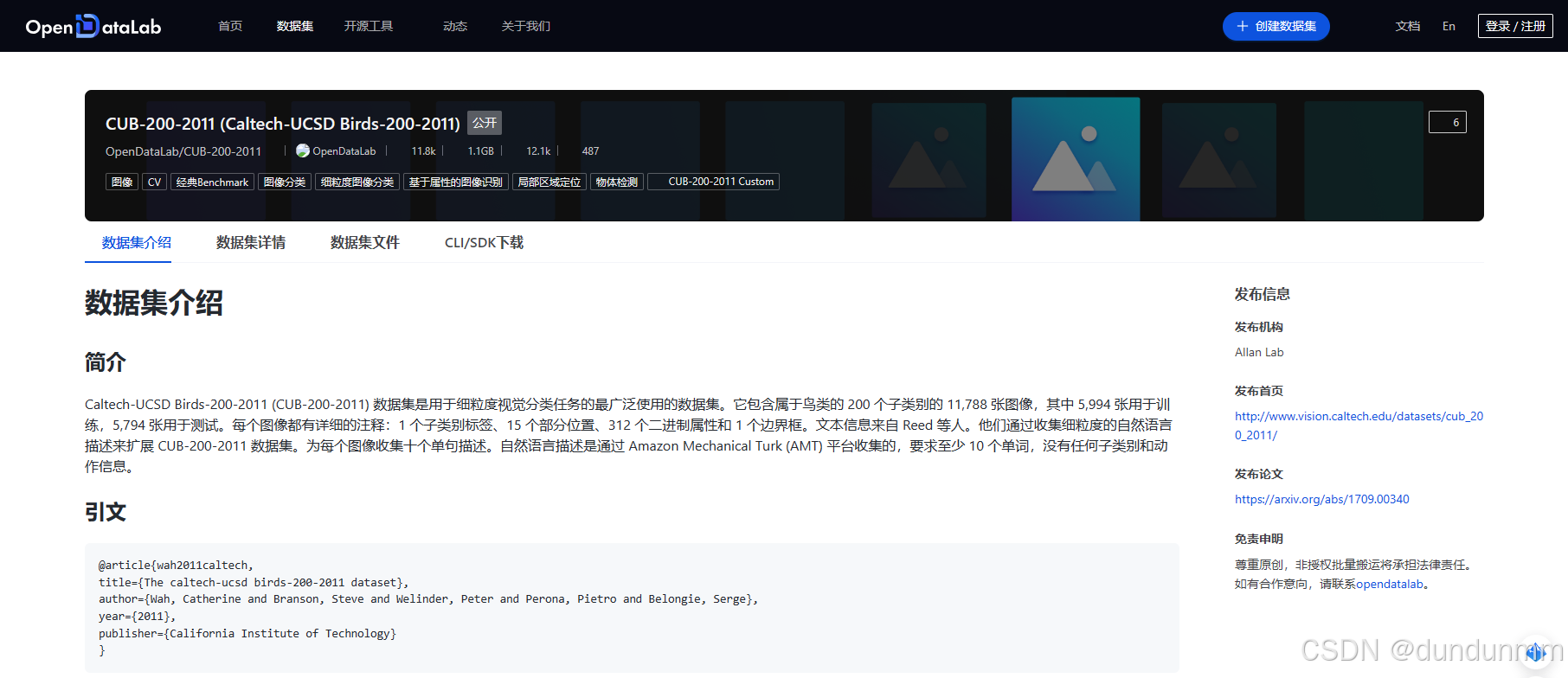
Caltech-UCSD Birds-200-2011 (CUB-200-2011) 数据集是用于细粒度视觉分类任务的最广泛使用的数据集。它包含属于鸟类的 200 个子类别的 11,788 张图像,其中 5,994 张用于训练,5,794 张用于测试。他们通过收集细粒度的自然语言描述来扩展 CUB-200-2011 数据集。为每个图像收集十个单句描述。扩展,CUB-200-2011 包括为每张图像
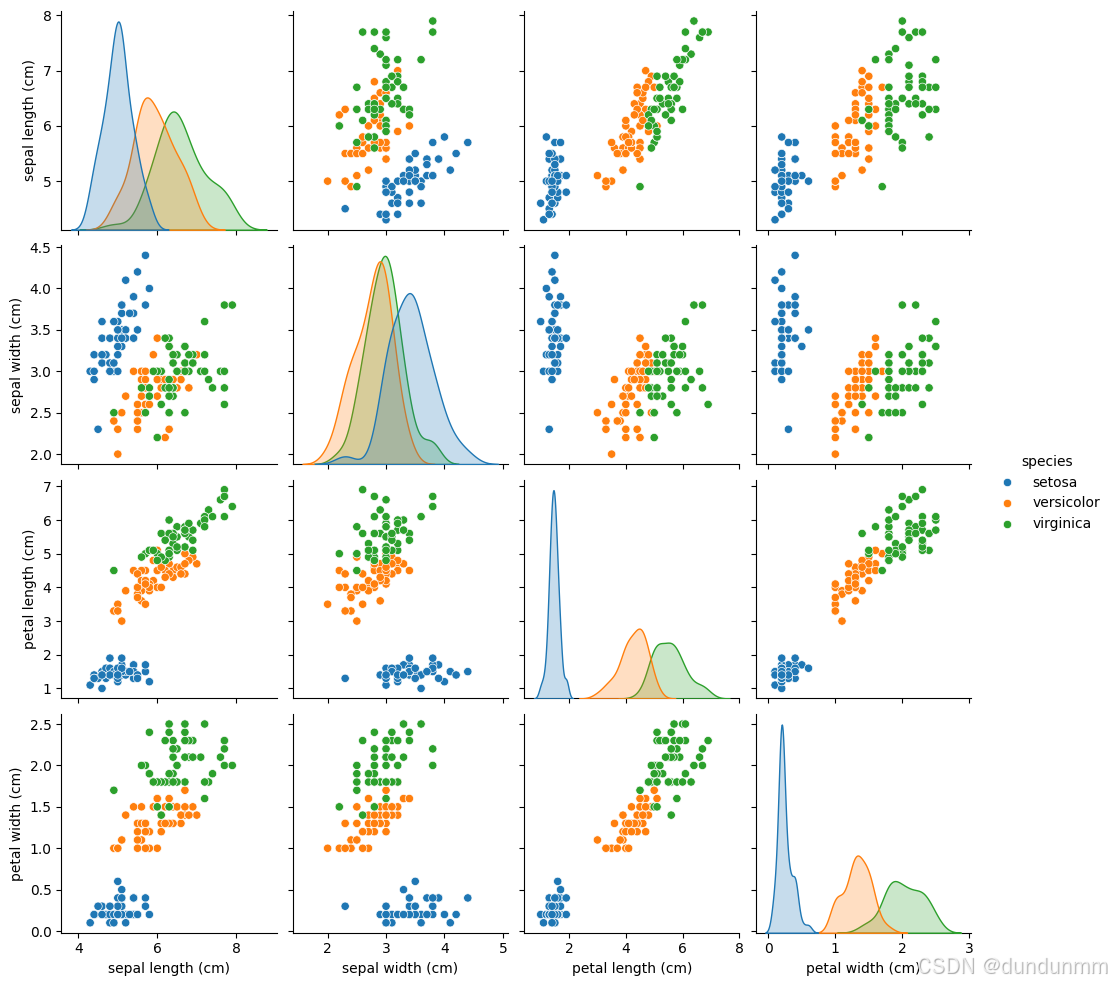
数据下载与加载: 使用加载数据,并通过pandas查看数据。统计描述: 使用describe()查看数据的基本统计信息。可视化: 使用seaborn绘制成对关系图、箱线图和热力图,了解数据的分布和特征之间的关系。缺失值处理: 使用pandas处理缺失值(在实际情况中常见)。通过这些方法,可以掌握如何处理数据、理解数据以及如何为后续分析做好准备。

高斯过程以其灵活性和不确定性量化能力,在小样本机器学习问题中表现出色。但其高计算复杂度限制了在大规模数据集上的应用,因此通常结合稀疏高斯过程或分布式方法来改进扩展性。

自编码器(Autoencoder, AE)是一种无监督学习模型,主要用于特征提取、数据降维、去噪和生成模型等任务。它的核心思想是通过将输入压缩到一个低维的潜在空间表示(编码过程),然后再从这个潜在表示重构输入(解码过程),从而使得模型能够学习数据的内在结构。
