- @cjy_colorful0806
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
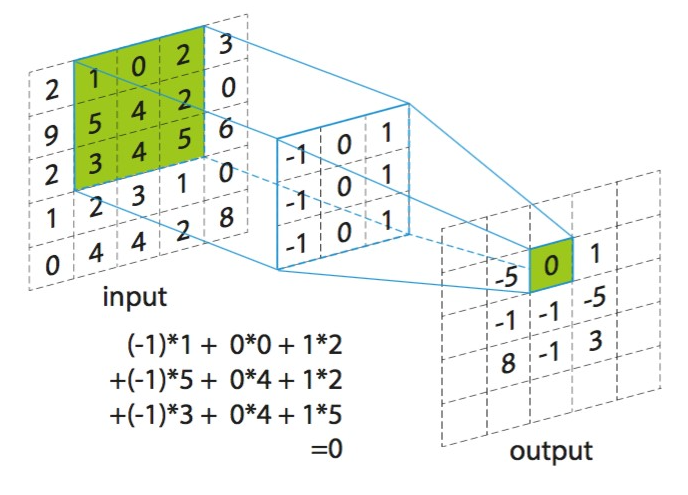
FLOPs(Floating Point Operations)是浮点运算次数的缩写,其计算包括所有的浮点数加法、减法、乘法和除法运算。在深度学习领域,FLOPs特别用来量化一个神经网络模型进行一次前向传播所需的浮点运算数量,这对于评估模型的计算效率和资源需求非常有用。
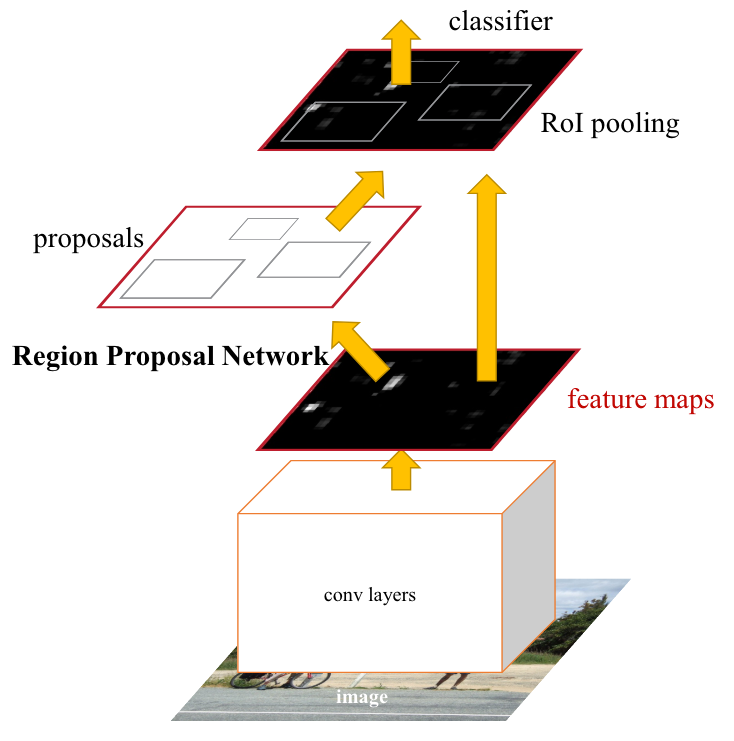
目标检测算法中,可以按照单阶段(One-Stage)和两阶段(Two-Stage)进行划分,也可以按照Anchor-Free和Anchor-based进行划分类型。不过,目前更流行的提法是后者。
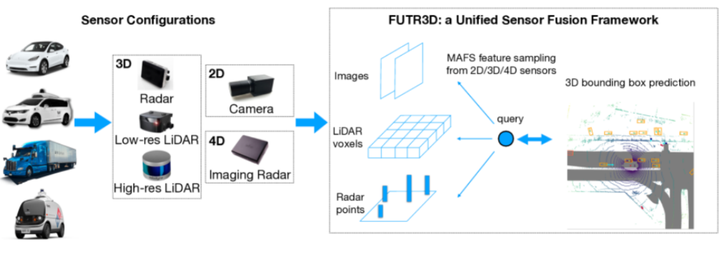
多传感器融合在自动驾驶系统中展示了其巨大优势。不同的传感器通常能提供互补的信息。例如,摄像头以透视视角捕捉信息,图像中包含丰富的语义特征,而点云则提供更多的定位和几何信息。充分利用不同传感器有助于减少不确定性,从而进行准确和鲁棒的预测。然而,由于不同模态的传感器数据在分布上的巨大差异,融合这些多模态数据一直是个挑战。当前的主流方法通常通过构建统一的鸟瞰图(BEV)表示来进行多模态特征融合,或通过查
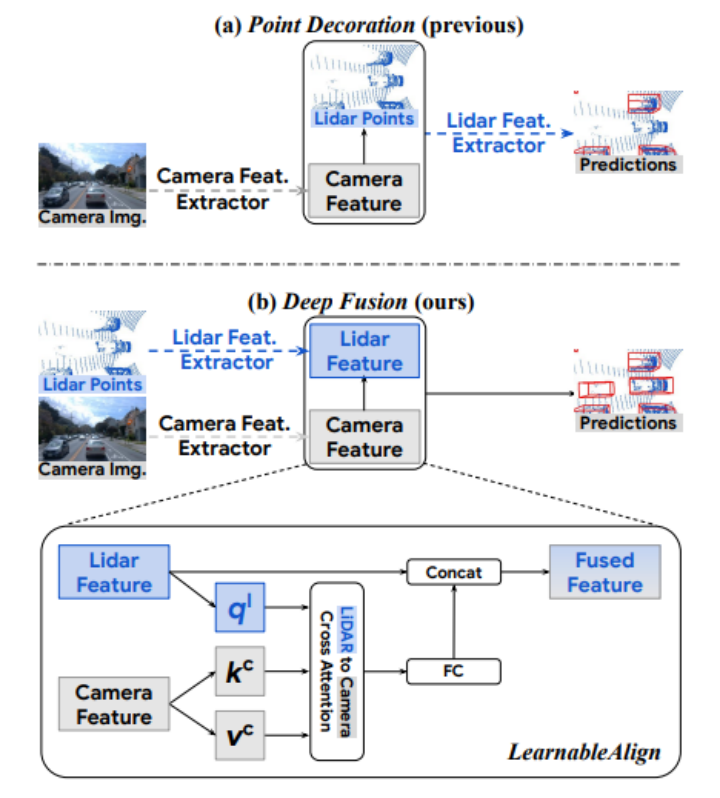
本文贡献:(1)第一个系统研究深度特征对齐对3D多模态检测器的影响(2)提出InverseAug 和LearnableAlign 来实现深度特征级对齐,从而实现准确且稳健的3D 对象检测器;(3)DeepFusions 在 Waymo 开放数据集上实现了最先进的性能
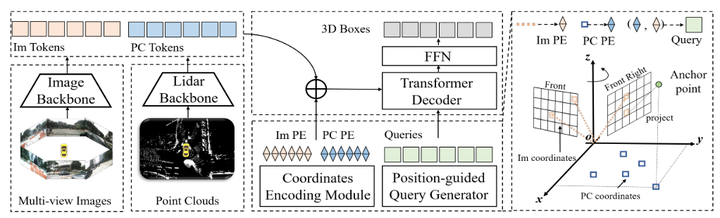
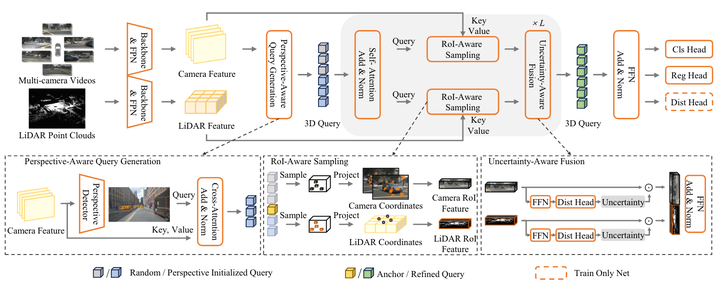
本文介绍了 SparseLIF,这是一种高性能完全稀疏多模态 3D 物体检测器,其性能优于所有其他密集对应检测器和稀疏检测器。 SparseLIF 通过在查询生成、特征采样和多模态融合三个方面增强丰富 LiDAR 和相机表示的感知来弥补性能差距。
上海期智研究院、复旦大学、CMU、清华大学、MIT、Li Auto无。
mean Average Precision(平均精度均值),它是目标检测和信息检索等任务中的重要性能指标。mAP 通过综合考虑精度和召回率来衡量模型的总体性能。

大模型已经成为发展AGI的重要途径,传统的专用模型是针对特定任务,一个模型解决一个问题,比如ImageNet竞赛中涌现的分类模型,AlphaFold等等。而通用模型旨在利用一个模型完成All任务,对应多种模态。比如GPT4通过Prompt实现。

【深度学习】Pytorch框架的入门简易代码模板及解析
如果存在此选项,则使用它。修改配置文件,需要根据步骤2. 模型推理框架并加载模型中选用的模型推理框架与加载的模型进行模型接入配置,具体参考model_settings.yaml中的注释。默认知识库位于CHATCHAT_ROOT/data/knowledge_base,如果你想把知识库放在不同的位置,或者想连接现有的知识库,可以在这里修改对应目录即可。-i, --incremental:本地文件夹中