- @bulling
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
伯努利分布(Bernoulli Distribution)是概率论中一种离散概率分布,描述只有两种可能结果的单次随机试验。MLE的核心思想是找到使观测数据出现概率最大的参数值。的先验分布是均匀分布时,即先验分布为常数时,最大后验估计与最大似然估计重合,因为此时。优化时需同时考虑似然和先验的权重(如L2正则对应高斯先验)。通过优化算法(如梯度下降)求解使对数似然最大的参数。MAP在MLE的基础上引入
本文介绍了LLAMA模型在Transformer架构上的两个关键改进:1) 使用Pre-RMSNorm替代Post-LayerNorm,通过仅对输入向量的均方根进行归一化,提高了计算效率和训练稳定性;2) 采用分组查询注意力(GQA)机制替代多头注意力(MHA),通过将查询分组并与共享的键值对交互,显著减少了KV缓存的内存占用。文章详细阐述了两种技术的数学原理、实现细节和性能优势,并提供了PyTo
逻辑回归是一种基于Sigmoid函数的二分类模型,通过线性组合和概率映射实现预测。其核心是交叉熵损失函数和梯度下降优化,适用于线性可分数据和大规模稀疏特征场景。优点包括计算高效、可解释性强,但存在对非线性数据拟合不足、易受多重共线性影响的缺点。相比树模型,逻辑回归是参数化线性方法,而树模型能自动处理特征交互和非线性关系。针对多重共线性问题,可采用特征筛选、正则化或PCA等方法解决。逻辑回归特别适合
参数模型,非参数模型,生成式模型,判别式模型,模型选择和评估

描述了潜在语义分析中的单词向量模型和话题向量模型,以及两者之间的映射和推到;然后介绍了概率潜在语义分析的基本概念,生成模型和共现模型
Llama采用的旋转位置编码(RoPE)相比传统sin/cos编码具有显著优势。RoPE通过旋转矩阵将位置信息融入词向量,保持模长不变仅改变方向,而sin/cos编码是简单叠加。关键区别在于:RoPE能显式建模相对位置关系(通过矩阵差),而sin/cos需隐式学习。RoPE优势包括:更好的长序列外推能力(利用旋转矩阵线性性质)、显式相对位置建模、保持向量空间稳定性以及更高计算效率。这种"
深度学习中过拟合和欠拟合的处理方式
介绍了聚类算法中常用知识点,包括距离或相似度,类间距离的定义,以及层次聚类和Kmeans聚类算法
介绍常见机器学习模型的优缺点,比如逻辑回归,k近邻,朴素贝叶斯,支持向量机
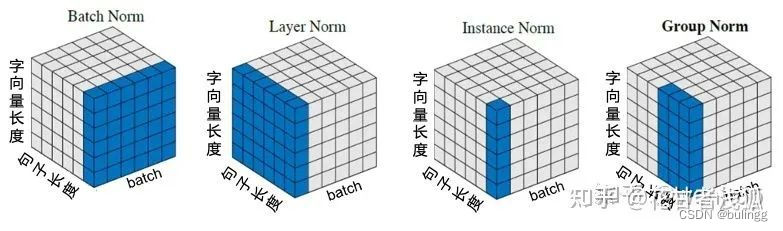
归一化在深度学习中的应用包括批量归一化(Batch Normalization)、层归一化(Layer Normalization)、组归一化(Group Normalization)和实例归一化(Instance Normalization)等。这些技术在不同的网络结构和任务中有着广泛的应用,是现代深度学习架构中不可或缺的一部分。Batch Norm:把每个Batch中,每句话的相同位置的字向量