




- @basketball616
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
现代C++中,Lambda表达式已成为核心工具,它通过简洁的匿名函数语法显著提升代码质量。Lambda的核心在于捕获列表,支持值捕获([x])、引用捕获([&x])及混合方式,并能通过mutable修改值捕获的副本。典型应用场景包括:1)与STL算法配合实现数据筛选、排序等操作;2)作为回调机制用于事件处理和异步编程。相比传统函数对象,Lambda减少了样板代码,使逻辑表达更直观,同时通过

Lambda 表达式本质是匿名函数对象,没有自己的名字,这让递归变得有些棘手。但实际上有多种方法可以实现 Lambda 递归,每种都有其适用场景。

Linux 文本处理工具摘要 sed 命令 流编辑器,用于文本替换、删除、插入等操作 常用选项:-i(直接修改文件)、-n(安静模式) 核心命令:s(替换)、d(删除)、p(打印)、a/i(追加/插入) 示例:替换文本、删除行、打印特定行、多命令组合 awk 命令 强大的文本分析和数据处理工具 按列处理数据,支持变量和函数 内置变量:$0(整行)、$1(第一列)、NF(字段数)、NR(行号) 常用

Redis持久化机制解析:RDB快照与AOF日志的完美结合 摘要:Redis通过RDB和AOF两种持久化方案保障内存数据安全。RDB采用快照模式,定期全量备份,恢复快但可能丢失数据;AOF记录每条写命令,数据更安全但恢复较慢。Redis 4.0+引入混合持久化,结合两者优势:RDB做全量备份,AOF记录增量修改。生产环境建议同时开启RDB和AOF,或使用混合模式,根据业务需求选择不同策略平衡性能与
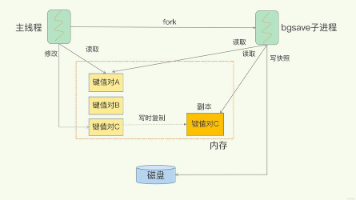
Redis基本命令速查指南 本文分类整理了Redis核心命令,涵盖字符串、哈希、列表、集合等数据类型操作。通过场景化示例讲解命令用法,帮助开发者快速掌握Redis基础操作。包括键值存取、数据结构管理、过期设置等实用命令,适合Redis初学者作为日常参考手册。文中所有命令均经过redis-cli环境验证,可直接用于实际开发。掌握这些命令可覆盖Redis大部分基础使用场景,为深入学习Redis高级功能

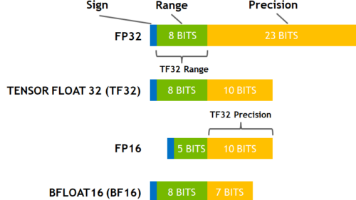
CUDA混合精度计算指南摘要 本文系统介绍了CUDA混合精度计算的核心原理与工程实践。混合精度通过非关键路径使用低精度(FP16/BF16)提升性能,关键路径保留高精度(FP32)确保准确性,可带来16倍算力提升、显存减半和带宽效率倍增三重收益。 文章详细解析了四种主流浮点格式(FP32、FP16、BF16、TF32)的位结构、动态范围和适用场景,指出BF16是训练首选、FP16适合推理、TF32
iomanip>
C++的new/delete与C的malloc/free本质区别在于:new/delete是运算符,会调用构造函数/析构函数,并自动计算内存大小,返回类型安全的指针;而malloc/free只是函数,仅处理原始内存分配释放。关键差异包括:new失败抛出异常,malloc返回NULL;new支持重载,malloc不能;必须配对使用new/delete或malloc/free,混用会导致未定义行为。在

数据 + 函数,程序是一系列操作的流水线。数据丢进去,函数处理,输出结果。对象 = 数据 + 行为,程序是对象之间通过消息进行交互。// 面向过程:数据和操作分离// 面向对象:数据和操作封装在一起public:本质转变:从"我该做什么"变成"谁来做这件事"。这种思维方式的转变是 OOP 的核心。抽象是定义一个接口,而不提供完整实现。在 C++ 中通过纯虚函数和抽象类实现。class Shape

本文深入解析了C++析构函数的关键知识点:1)析构函数是对象销毁时自动调用的特殊成员函数,负责资源清理;2)详细说明了析构函数的调用时机,包括作用域退出、delete操作等;3)重点强调了三大核心原则:禁止抛出异常、基类析构必须为虚函数、纯虚析构需要定义;4)解释了虚析构的实现原理;5)阐述了析构函数与三/五法则的关系;6)介绍了RAII设计模式及其在资源管理中的应用;7)说明了继承体系中的构造和
