- @Z4400840
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
这篇文章推荐了一个零基础学习AI Agent搭建的教程资源包,包含168页系统化资料和配套代码。作者分享了自己从零实操的经验,整理了搭建步骤、常见问题和技巧,帮助新手快速入门。资料免费提供,适合想入局AI Agent但受困于碎片化信息的学习者。通过2.5小时的学习即可掌握基础搭建技能,无需深厚技术背景。文末附有获取链接。
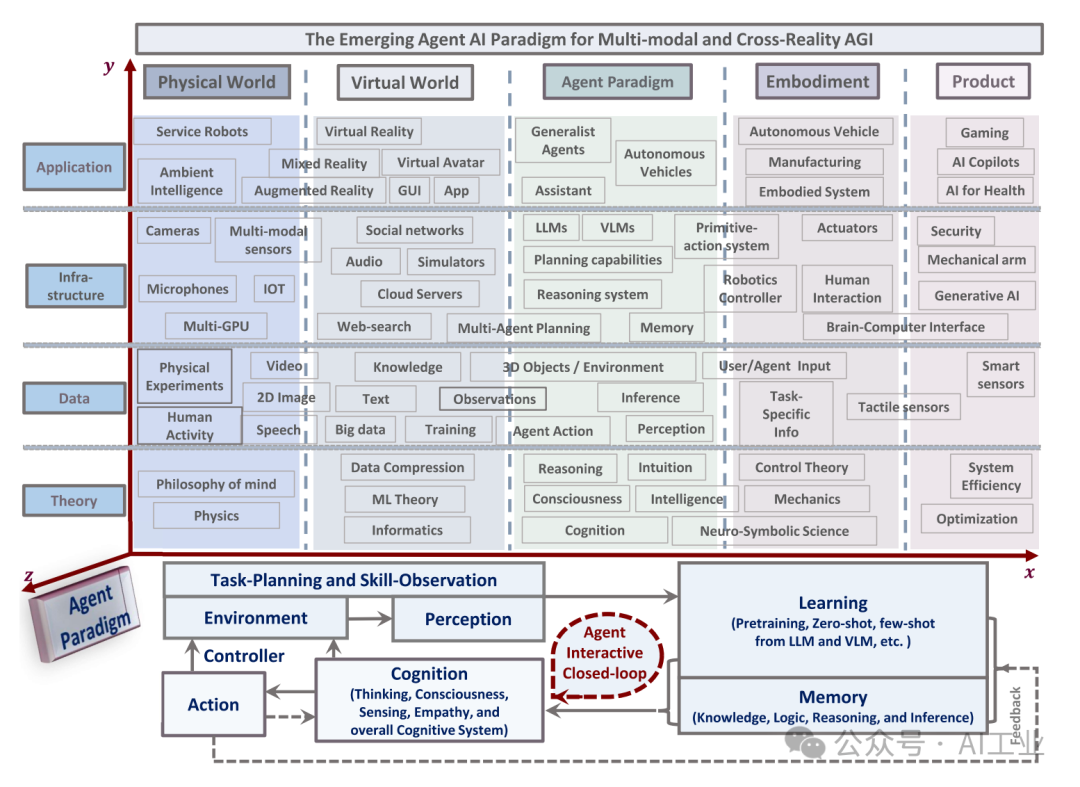
多模态代理AI(MultimodalAgentAI,MAA)是一类基于多模态感知输入理解而生成有效动作的系统。随着大语言模型(LLM)和视觉语言模型(VLM)的发展,许多MAA系统在从基础研究到应用的各个领域中不断涌现。尽管这些研究领域通过结合各自领域的传统技术(如视觉问答和视觉导航)迅速发展,它们在数据收集、基准测试和伦理视角方面具有共同的关注点。本文着眼于MAA的一些代表性研究领域,包括多模态
Ollama 是一个开源工具,支持在本地便捷部署和运行大语言模型(LLM)。文章详细介绍了其安装方法(支持MacOS、Windows、Linux及Docker容器运行)、模型下载与运行、自定义模型导入、系统提示配置等核心功能。同时涵盖了CLI命令、REST/Python API、日志调试、服务化部署、模型存储管理以及OpenAI兼容性等实用技巧。特别针对企业本地化部署需求,提供了CPU/GPU模式

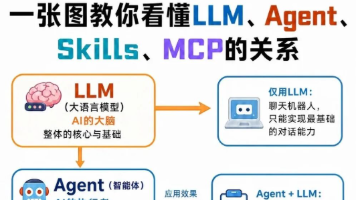
这篇文章用通俗易懂的方式解释了AI领域的核心概念:LLM(大语言模型)是AI的大脑,负责基础认知;Agent(智能体)是AI的执行系统,相当于手脚和管家;Skills(技能)是Agent的工具包,赋予其特定能力;MCP(模型控制平台)则是企业级AI的中控台。文章指出,单纯使用LLM只能构建聊天机器人,结合Agent和Skills可实现个人自动化助手,加入MCP后就能开发企业级AI应用。文末还提供了
摘要: RAGFlow是一款基于深度文档理解的开源RAG(检索增强生成)引擎,旨在解决当前RAG技术存在的幻觉、拒答和回答不完整等问题。它支持多种文件格式(如PDF、Word、Excel等),通过智能模板化分块技术实现可控可解释的文本处理,并采用多路召回与融合重排序提升检索精度。RAGFlow的核心能力包括深度文档解析(如OCR、布局识别)、可视化分块调整及精准知识提取,确保生成回答的准确性和可追
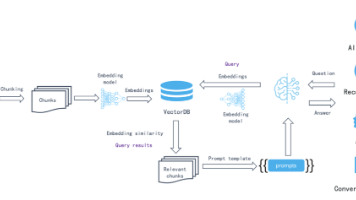
2024年被称为Agent元年,AI智能体正快速渗透各行业。Agent具备自主性、交互性、反应性和适应性四大特征,技术演进从1986年概念提出到2025年"自主思考"阶段。为提升协作效率,Anthropic推出MCP协议实现AI与工具连接,Google提出A2A协议解决多Agent协同问题。未来,Agent将在企业服务、医疗、制造等领域广泛应用,技术巨头纷纷布局。随着标准协议完
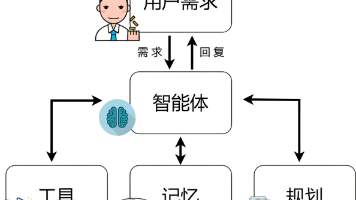
本文介绍了三种主流的智能客服设计方案:1)基于开源LLM模型微调;2)检索增强生成(RAG)方法;3)结合前两者的多工作流Agent方案。重点分享了智能客服Agent技术的实践经验,通过引入深度学习、多轮对话跟踪等技术,将意图识别准确率提升至92%,用户满意度显著提高。文章涵盖从需求分析到生产部署的完整技术链路,包括多轮对话维护、知识库集成等核心环节。该方案已在多家企业成功落地,日均处理10万+对
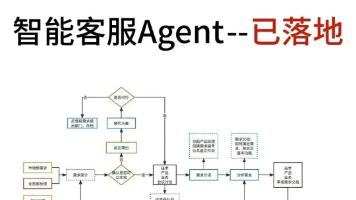
文章解析了企业级AI Agent的四大工程化趋势:MCP实现可扩展连接、GraphRAG确保回答一致性、AgentDevOps提供可控性、RaaS实现结果导向计费。这些技术使AI Agent从辅助工具转变为可承担岗位职责的"硅基员工",接受KPI考核。通过金融、HR等领域的实际应用案例,展示了AI Agent如何解决落地难题,并提供了企业级AI Agent落地的自检清单。
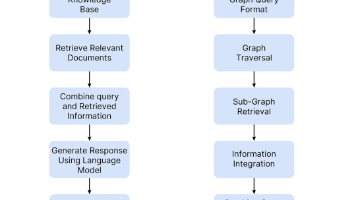
文章详细解析了AI产品经理的三种发展方向:业务导向型(深耕特定行业场景)、平台型(构建技术基础设施)和技术导向型(专注数据价值挖掘)。文章分析了各类型的核心能力、适合人群、转型路径及职业前景,帮助从业者根据自身背景和优势选择适合的发展方向,在技术可行性、商业价值和用户体验的三角模型中找到独特定位,成为技术与业务之间的翻译官。
系统定位为 “基于AI的一站式知识管理与分析决策平台” ,旨在为政府、央企、国企及大型IT集成商等客户提供私有化、自主可控、深度智能的知识管理解决方案。平台深度融合了检索增强生成(RAG)、全文搜索、知识图谱、MCP、多模态处理、大语言模型等前沿AI技术,致力于解决传统知识管理的根本性问题。