- @YYDS_54
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文探讨了Claude第5代模型的核心改进——通过"上下文工程"大幅精简系统提示(砍掉80%),使模型不再依赖人工预设的复杂规则。文章对比了新旧范式的六组差异:从硬性规则转向信任模型判断力、从示例教学转向接口设计、从信息堆砌转向渐进披露等。作者建议在构建AI代理时,将系统提示聚焦产品定位,CLAUDE.md记录关键注意事项,Skills封装独特经验,References提供高保真素材。最后介绍了自

这篇文章不是概念科普,是一份能直接落地的手册。我会先把"图"到底是什么讲清楚(包括一个最容易踩坑的"假边"概念),再给一个我认为今年最值得掌握的模式,然后三个能直接抄的构建,最后收一份操作清单。所有 prompt 我都保留了英文原样——像 Claude Code 这类工具对英文指令里的"编排意图"识别更稳,复制即可用;如果你用 LangGraph / CrewAI / 自研 DAG 调度,思想完全
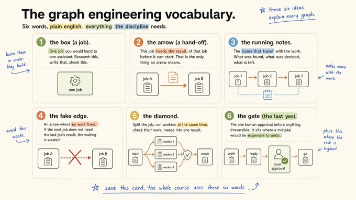
规约到关键点,合成一个连贯叙述。Claude 工作流里,扇出是 parallel(),规约是 .filter().map() 等纯代码,合成是一个对规约结果操作的 Agent。规约层是零 Token 的——把 Agent 留给需要判断的地方。 08 · 管道:节点按顺序传递数据 扇出给广度,管道给深度。当节点 B 消费节点 A 的全部输出时,它们是一条管道——A 的输出是 B 的输入,没有其他东西
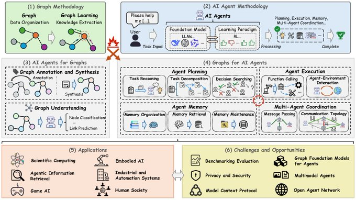
这篇文章介绍了Claude AI的四个隐藏功能:Projects(项目记忆)、Artifacts(交互应用)、Adaptive Thinking(深度推理)和Memory(个人信息记忆)。每个功能都配有具体开启方法和实用prompt模板,能显著提升工作效率。文章特别强调这些被多数用户忽略的功能可以改变Claude的基础使用体验,使其从普通对话工具转变为个性化工作助手,并提供心理咨询师、严厉导师等角
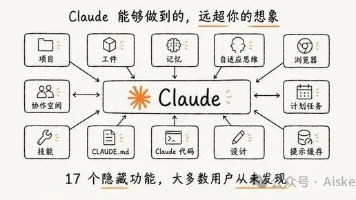
这篇文章介绍了Claude AI的四个隐藏功能:Projects(项目记忆)、Artifacts(交互应用)、Adaptive Thinking(深度推理)和Memory(个人信息记忆)。每个功能都配有具体开启方法和实用prompt模板,能显著提升工作效率。文章特别强调这些被多数用户忽略的功能可以改变Claude的基础使用体验,使其从普通对话工具转变为个性化工作助手,并提供心理咨询师、严厉导师等角
这篇文章介绍了Claude AI的四个隐藏功能:Projects(项目记忆)、Artifacts(交互应用)、Adaptive Thinking(深度推理)和Memory(个人信息记忆)。每个功能都配有具体开启方法和实用prompt模板,能显著提升工作效率。文章特别强调这些被多数用户忽略的功能可以改变Claude的基础使用体验,使其从普通对话工具转变为个性化工作助手,并提供心理咨询师、严厉导师等角
本文介绍了LangChain v1.0中智能体(Agents)的核心组件与实现方式。智能体通过结合语言模型与工具,构建能够推理任务、动态选择工具并迭代推进解决方案的系统。文章重点讲解了三个核心组件:1) 模型(Model)作为推理引擎,支持静态和动态选择;2) 工具(Tools)赋予执行能力,支持自定义错误处理和ReAct循环;3) 系统提示词(System prompt)用于塑造智能体行为。文中

要学习 LangChain 躲不过的就是它的几大核心组件,这些组件撑起了 LangChain 框架的重要功能,今天我们看一下 Models,这个组件到底应该如何应用,这也算是 LangChain 的功能起源了,调用大模型一般都是在这个组件下面,下面就让我们一起来看一看。

前阵子跟风装了OpenClaw,玩了两周新鲜劲过了,想卸载腾空间,随手敲了一行`npm uninstall -g openclaw`就以为万事大吉。结果没过几天,安全圈的朋友发了个预警,说常规卸载方式会留下大量凭证和配置文件,哪怕删了CLI工具,API密钥、OAuth令牌、聊天记录全躺在系统里。我回去一查,果然`~/.openclaw`目录完整存在,里面的明文密钥、历史对话、绑定的账号权限一点没少

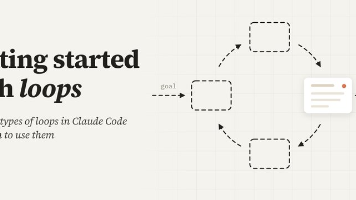
Claude团队发布工程指南《Getting started with loops》,首次系统拆解AI循环设计方法。文章将循环定义为"Agent重复工作周期直至满足停止条件",并按触发方式、停止条件、实现原语和适用场景四个维度分类,清晰区分了四种循环模式:轮次制循环(手动触发)、目标循环(量化验收)、时间循环(定时触发)和全自动循环(云端持续运行)。指南强调通过验证技能(Skill)提升循环质量,