




- @WYKB_Mr_Q
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
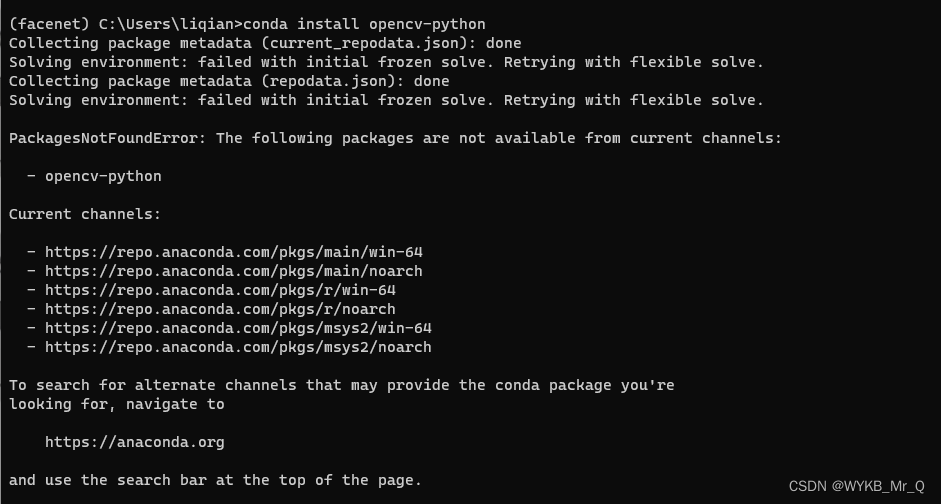
我的python版本是3.6的,当需要安装opencv时,使用。开始以为网络的问题,尝试了几次都没有成功。最后使用conda命令安装成功了,测试一下,安装成功。
机器学习中SVM、决策树、逻辑回归、K近邻算法python代码实现上篇文章咱已经叙述了如何从excel表中读取保存的数据特征及类别标签,这篇文章主要介绍机器学习中常用到的算法python代码实现方式,主要包括SVM、决策树、逻辑回归和K近邻算法。这是上篇文章中我们使用到的数据特征,前六列是特征向量,第七列是数据标签。这篇文章默认已经把数据读出来了(如果不会读取数据的小伙伴可以去看我的上一篇文章)。
在进行图像形态学操作时,首先需要构造一个特定的核,该核可以自定义生成,也可以通过函数构造。shape ---- 代表形状类型:代表矩形结构类型,所有元素值都是1:代表十字形结构类型,所有元素值都是1:代表椭圆形结构类型,所有元素都i是1ksize ---- 代表形状元素的大小。

方法1、首先我们要用到 skimage 第三方库,安装方法:pip install scikit-image2、代码部分,我们使用数据批处理方式:from PIL import Imagefrom skimage import util, img_as_float, io# 导入所需要的 skimage 库import osold_path = r"E:\relate_code\frame_res
Traceback (most recent call last):File "E:/relate_code/Gaitpart-master/main.py", line 149, in <module>train_model()File "E:/relate_code/Gaitpart-master/main.py", line 98, in train_modelloss = cr
实例分割任务是目标检测任务和语义分割任务的结合,需要同时完成实例级和像素级的预测,既要区分视频中不同的目标个体,又要目标轮廓进行精细分割,是一个复杂且有挑战性的任务。通过实例分割得到的输出结果,包含图像中像素是否属于目标的一个矩阵,该mask是由一个二维的布尔型数组组成,如下所示。此方法可以实现目标,并且速度非常快,经测验在1080*720的数组上,运行速度为0.002s。此方法可以实现目标,但是

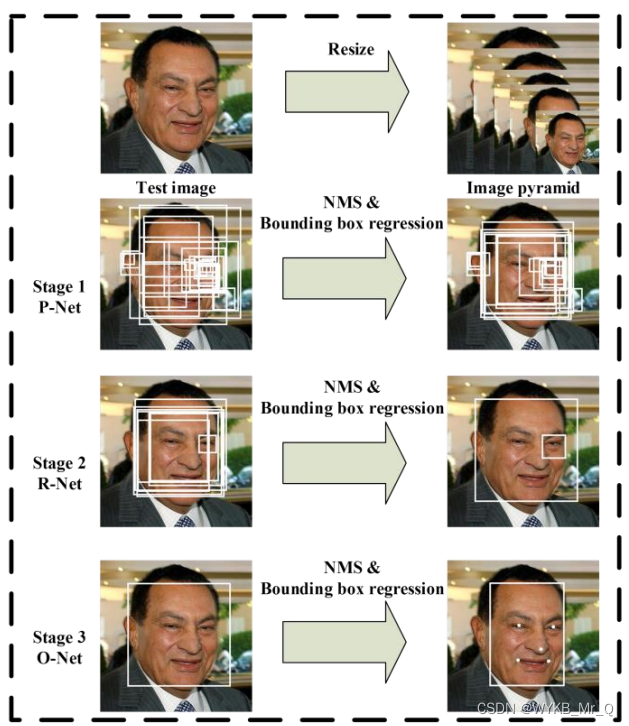
为了提高人脸识别的准确性,我们首先要把图像或视频中的人脸检测出来,然后使用分类网络,对检测到的人脸进行分类。在人脸识别部分,我们首先将想要识别的人脸图片存入文件夹,然后计算视频中检测到的人脸与文件夹内人脸的差异,根据阈值判断检测到的人脸是已知的,还是陌生人。下图是该网络的模型结构参数,可以发现该网络结构由简单的若干个卷积层组成,结构简单,运行十分快速,因此适用于在线的人脸识别。,它的模型结构如下图
pytorch框架其中stack()函数和cat()函数都是将两个输入组合成一个batch.stack函数二者的区别在于,stack()函数是将两个输入堆叠起来,维度会增加1。import torchx = torch.rand((2,2,3))y = torch.rand((2,2,3))z = torch.stack((x,y),dim=0)这样两个堆叠起来的 z 的维度是(2,2,2,3),
YOLOv8 已经出来一段时间了,它同时拥有目标检测,实例分割,关键点检测,跟踪和分类的功能,并且效果达到了SOTA,使得 YOLOv8 得到了很多科研人员的青睐。这里我们主要使用了 github 公布的。接下来,我们主要记录一下,如何自己制作关键点检测数据集,并跑通YOLOv8项目。YOLOv8项目中的关键点检测,也就是分支,主要是标注了人体的骨骼部分,来精炼表示人体运动,如下图所示。
深度相机可以获取RGB-D数据,不仅可以提取目标的可将光图像,同时还能获得目标距离相机的深度信息。深度相机在测距、三维重建、动物体尺体况分析等多个方面具有广泛的应用潜力。目前,市面上的深度相机包含多个品牌,包括Kinect系列、Intel RealSense系列以及奥比中光系列等,由于奥比中光相机开源了基于python的控制代码,大多深度学习的项目又都是基于python编写的,所以我们选择了奥比中
