




- @WH_G_Y
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
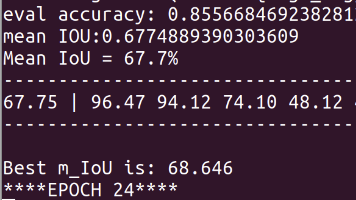
最近在学习基于深度学习的点云分割算法,关注到牛津大学胡庆拥博士提出的RandLa-Net网络应用于城市级别的点云语义分割,所以想来复现一下。复现过程所参照的博文和代码如下(排序不分先后。没有各位大佬的分享,晚辈们必定寸步难行,感激不尽)
1、假设绘制得到如下图窗,文件-导出设置-以600pi分辨率导出为jpg格式,图片两侧存在大量空白,需要到word中裁剪(如使用专门裁剪工具还会降低图片的清晰度)2、我们可以调整matlab图窗的大小(如下图所示,等待外侧图框的角点亮起,然后拖拽某一个角点调整图窗整体大小)4、最后再导出设置,可以发现,导出的图片大小与figure图窗大小一致,而且两侧没有空白区域。3、之后再选中内侧坐标区域,使得
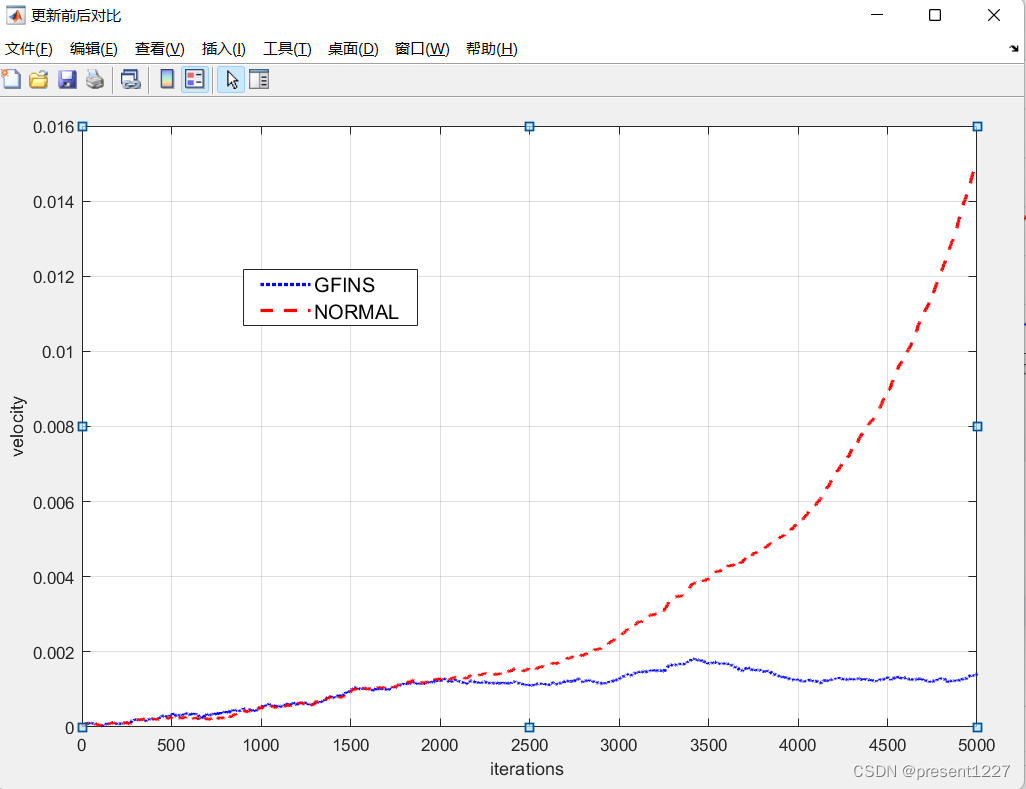
先用GLDAS水文模型的格网产品经过球谐分析得到球谐系数,再经过截断和高斯滤波或者去相关滤波处理得到滤波后的格网,逐格网点求解滤波前后的差异因子。发现经过尺度因子改正之后,泄漏至海洋的信号明显减弱,但是以长江流域为例,求EWH时间序列发现,乘以GRACE/GRACE-FO经过截断和滤波后的格网数据得到尺度因子改正后的解。3、 将GLDAS滤波前和滤波后的格网按时间序列排列进行最小二乘求尺度因子。2

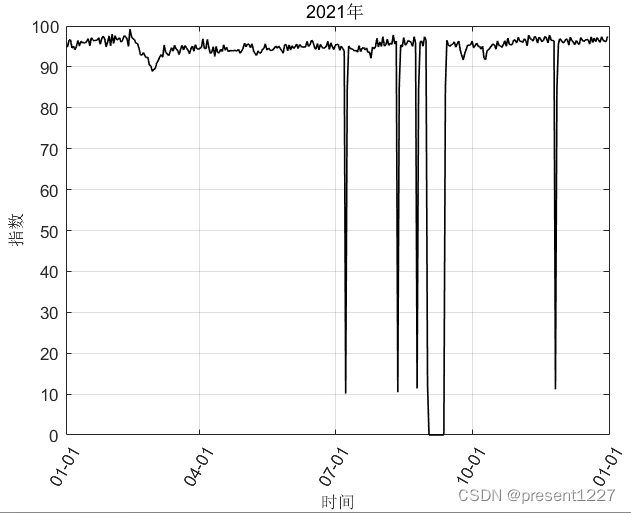
导入 matlab中,为数值矩阵;Excel表格中有类似于如下 年月日对应的数据。
本文介绍如何在Windows10/11系统下使用Anaconda(Python3.8)和Spleeter工具实现音频分离。主要内容包括:1)创建Python3.8独立环境;2)安装必要的音频处理依赖;3)配置Spleeter及TensorFlow环境;4)下载并放置预训练模型;5)设置环境变量;6)执行音频分离操作。该方法无需GPU支持,可将音频分离为人声和伴奏两个音轨,支持mp3/wav/mp4
本文介绍如何在Windows10/11系统下使用Anaconda(Python3.8)和Spleeter工具实现音频分离。主要内容包括:1)创建Python3.8独立环境;2)安装必要的音频处理依赖;3)配置Spleeter及TensorFlow环境;4)下载并放置预训练模型;5)设置环境变量;6)执行音频分离操作。该方法无需GPU支持,可将音频分离为人声和伴奏两个音轨,支持mp3/wav/mp4
Kusche 等(2007)从时变重力场模型球谐系数求解出发,对球谐系数的最小二乘解的法方程组应用贝叶斯估计,构造了 DDK 滤波。

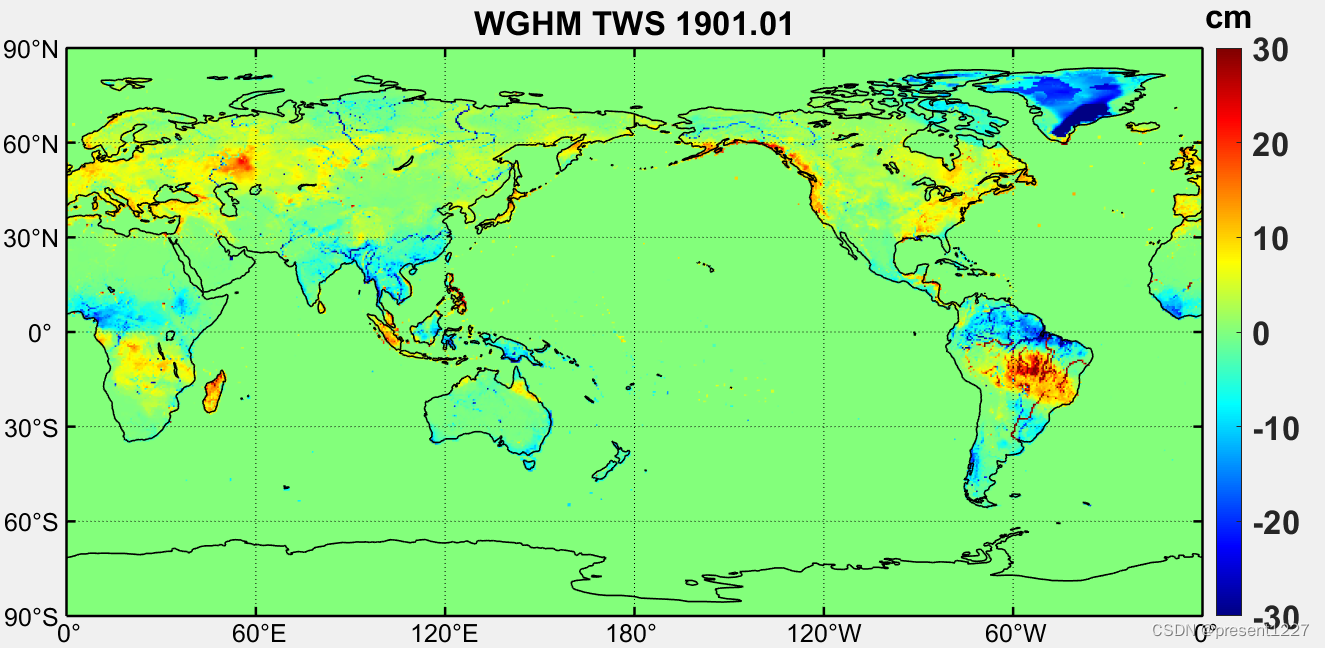
找到缺失值NaN赋值为0。利用冯伟老师的“GRACE_Matlab_Toolbox-master”工具包绘制全球格网图。%截取1901年的数据。%将数据中的缺省值替换为0。下载对应水文分量的”nc4”文件,以TWS为例,利用如下matlab代码读取。
首先以等效水柱高形式绘制测量信号的阶方差图像,再运用上述前两个公式进行最小二乘拟合,求得拟合参数a、b、c、d,最后利用第三公式计算滤波系数h(注意:对于最大阶数60的球谐产品,上述第一个公式适用于0-20阶,第二个公式适用于31-60阶数)示例代码中滤波半斤r0=200km、r1=300km、选定的次m1=15,绘制滤波系数图如下。

以GLDAS数据为例,展示利用IDM软件进行批量下载
