- @Gabriel100yi
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
媒体称,该壁挂式显示器定位为家庭指挥中心,可控制家电并使用AI导航App,屏幕约6英寸,大小相当于两部iPhone并排,正面顶部有一个摄像头。该设备有触摸界面,但苹果预计大多数人会使用依靠Siri的语音与它交互。稍早郭明錤称,苹果将首次推出智能家居网络摄像头,深度结合Apple Intelligence和Siri,计划2026年量产。

该计划的一个关键是利用美国进出口银行等机构,推动美国制造的芯片和AI工具的出口,同时加速数据中心的审批流程。前几日,特朗普已宣布900多亿美元的AI投资计划。此外,该计划还将致力于大幅简化数据中心的建设审批流程,并为这些高耗能设施的能源供应提供便利,以满足AI产业对算力基础设施的爆炸性需求。根据一份长达20页的计划草案,该行动计划将主要阐述政府对AI发展的愿景和目标,包括促进创新和减少监管负担。即

根据一些早期测试,这个模型强的离谱,可以一键生成我的世界和侠盗猎车手,在前端编码方面达到了完全不同的水平——远胜于 Sonnet、o3、Gemini 2.5 Pro 或 Grok 4。OpenAI 神秘新模型正在测试中,迅速刷爆了时间线,根据一些早期测试,这个模型强的离谱,可以一键生成我的世界和侠盗猎车手,在前端编码方面达到了完全不同的水平——远胜于 Sonnet、o3、Gemini 2.5 Pr
收入角度,我们对海外6月ARR口径排名前100应用进行统计,收入总规模达到333.7亿美元,其中两家模型公司OpenAI(100亿美元)+Anthropic(30亿美元)收入占到约39%,前五名应用占到64%;2)营销工具领域:AppLovin等企业通过Axon引擎等技术,实现广告投放全链路AI优化,拓展金融科技、CTV(Connected TV,网联电视)等非游戏垂类,构建 “广告主-开发者”双

这是一个监督学习问题,我们通过分析欺诈(fraud)和非欺诈(non-fraud)交易案例的信用卡交易数据集,开发一个机器学习模型来检测欺诈性信用卡交易,这对于金融机构增强安全性、保护用户免受欺诈活动并使不同交易的环境变得非常容易至关重要。在这个项目中,我们利用带有标记音频剪辑的数据集,例如包含情感语音录音的“RAVDESS”数据集,开发一个可以识别口语中不同类型的情绪(愤怒、快乐、疯狂等)的模型

历次降息周期中,债券资产在降息前超额优势明显,美股其次,沪金和权益类资产也可能取得超额收益。

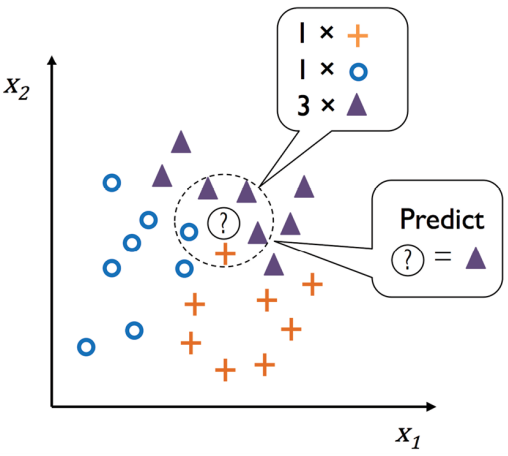
随机森林里面包含了多棵决策树,我们可以通过计算特征在每棵决策树决策过程中所产生的的信息增益平均值来衡量该特征的重要性。我们可以通过 scikit-learn 提供的 SelectFromModel 来通过 threshold 参数设定一个阈值 ,选择满足这个贡献度阈值的特征出来。可以看到选择了 5 个特征,现在我们就用这 5 个特征拟合一下 kNN 算法。选择 5 个特征时,模型在训练集和测试集上

然而,不利的一面是,在最坏的情况下,对新样本进行分类的计算复杂性会随着训练数据集中的样本数量而线性增长,除非数据集的维度(特征)非常少,并且算法已使用高效的数据结构(比如 k-d 树,ball tree)实现,以便更有效地查询训练数据。基于实例学习的模型的特点是记忆训练数据集,而懒惰学习是基于实例的学习的一种特例,在学习过程中没有(零)成本。根据我们选择的样本间距度量指标,kNN 算法选择离新的样
人形机器人目前既不够有用,又拉不开差距”,一位投资人表示。过去一周,我们仿佛能在世界机器人大会上看到全世界的机器人,600余件相关展品几乎覆盖了机器人的各条产业链。机器人类型也多得令人眼花缭乱,比如“上蹿下跳”的机器狗、整齐划一“摇曳”的机械臂,还有可以做到不把酒撒出来的“送餐小能手”等。不论是机器人数量还是参展热度,人形机器人都堪称“C位”。据官方表示,这是人形机器人数量最多的一届大会,而现场几

整体来看,营收仍是一片倒,有的下滑严重,唯有少数大厂实现增长,各家恢复的状况很不均衡。国内厂商除MCU,同比皆有所增长。