- @FYZDMMCpp
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
译自Pretrained Language Models for Text Generation: A Survey 第六节数据角度小样本学习:在许多任务中,获取足够标记数据既困难又昂贵。预训练模型可以编码大量的语言和现实知识,这为数据稀缺提供了有效的解决方案。通常采用的方法是使用预训练参数插入现有模块。然后用几个、一个甚至没有研究任务的case对它进行微调。比如将小样本学习应用于数据到文本的任务
译自Pretrained Language Models for Text Generation: A Survey 第六节数据角度小样本学习:在许多任务中,获取足够标记数据既困难又昂贵。预训练模型可以编码大量的语言和现实知识,这为数据稀缺提供了有效的解决方案。通常采用的方法是使用预训练参数插入现有模块。然后用几个、一个甚至没有研究任务的case对它进行微调。比如将小样本学习应用于数据到文本的任务
有人看了我之前写的那篇《让深度学习歇一会》,过来跟我说,我可以再写一篇《大数据带来的歧视》:基于大数据的业务越来越多,我们所遭受的歧视也越来越多,比如今天发现某银行对大专生的贷款利率是大学生的利率的1.5倍…………数据偏见其实是早就被谈烂的话题了,有一本书叫《算法霸权》,很多人应该都看过。这本书讲的就是数据偏见。我觉得这本书的观点有可取的地方,但是很少。一方面它只有几个立论,只是在用不同的论据、换
现代投资组合理论有很多分支,如:投资组合理论、资本资产定价模型、套利定价模型、行为金融理论以及有效市场理论等。这些理论改变了人们对资产管理的传统认知,促使现代的资产管理更系统化和更科学化的发展。1952年,经济学家Markowitz发表了《证券组合选择》,其中建立了均值–方差模型,并且对收益和风险进行了量化,从而确定了最优的资产组合基本模型。这项研究成果使现代金融理论的研究进入了一个崭新的阶段。不
为什么需要策略梯度基于值的强化学习方法一般是确定性的,给定一个状态就能计算出每种可能动作的奖励(确定值),但这种确定性的方法无法处理一些现实的问题,比如玩100把石头剪刀布的游戏,最好的解法是随机的使用石头、剪刀和布并尽量保证这三种手势出现的概率一样,因为任何一种手势的概率高于其他手势都会被对手注意到并使用相应的手势赢得游戏。再比如,假设我们需要探索上图中的迷宫拿到钱袋。如果采用基于值的方法,在确
目前,人们主要通过三种方式来获取三维模型:利用传统几何造型技术直接构造模型利用三维扫描设备对真实物体进行扫描,进而重建出模型利用从各个视角拍摄的真实物体的多幅图像重建模型由图像重建三维模型技术又可分为两类:一类是通过多幅深度图像重建模型,另一类是通过多幅照片生成物体的可视外壳。Visualhull(可视外壳)是由Laurentini引入的有形状到轮廓的3D重建技术构建的几何实体...
符号运算系统最有用的一项特性就是数学表达式的化简。SymPy中有许多能够进行不同类型表达式化简的函数。其中,有一个通用的函数名为simplify,它能够试图以一种智能的方式应用这些化简函数,并最终得到表达式的最简形式。下面给出一个simplify的例子:>>> simplify(sin(x)**2 + cos(x)**2)1>>
前言:2014年,Deepmind提出了神经图灵机。其后,各种传统软件系统的可微版本被提出,基于自动微分框架的反向计算能力,神经网络被应用于大量新颖的场景。基于这些事实,一些机器学习外围的理论研究人员认为,由于神经网络与图灵机的计算模型(可以被认为)等价,因此可以解决一切有价值的问题;或者认为,一切人脑有可能解决的问题,都可以通过深度学习解决。昨天在刷知乎的时,针对这一观点,我与一个同学展开了讨论

使用有监督学习方式,基于GPT3.5微调训练一个初始模型;训练数据约为2w~3w量级根据InstructGPT的训练数据量级估算,参照P33 Table6),由标注师分别扮演用户和聊天机器人,产生人工精标的多轮对话数据;值得注意的是,在人类扮演聊天机器人时,会得到机器生成的一些建议来帮助人类撰写自己的回复,以此提高撰写标注效率。以上精标的训练数据虽然数据量不大,但质量和多样性非常高,且来自真实世界
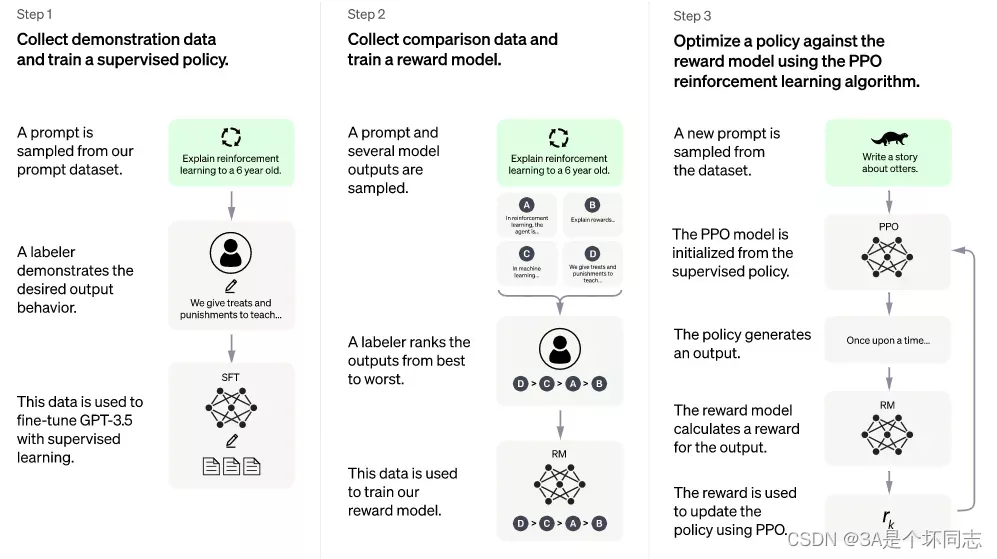
使用有监督学习方式,基于GPT3.5微调训练一个初始模型;训练数据约为2w~3w量级根据InstructGPT的训练数据量级估算,参照P33 Table6),由标注师分别扮演用户和聊天机器人,产生人工精标的多轮对话数据;值得注意的是,在人类扮演聊天机器人时,会得到机器生成的一些建议来帮助人类撰写自己的回复,以此提高撰写标注效率。以上精标的训练数据虽然数据量不大,但质量和多样性非常高,且来自真实世界