




- @DuLNode
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
2026年主流编程大模型横向评测:DeepSeek V4-Pro以1.6T参数和1M上下文窗口展现全能表现,MiniMax M2.5以80.2% SWE-bench得分和100TPS推理速度成为性价比之王,GLM-5.1以58.4% SWE-benchPro得分创开源纪录,Qwen3-Coder-30B专注代码生成,Kimi-K2擅长思维链推理,MiniMax M2.7强化多智能体协作能力。评测涵

2026年主流编程大模型横向评测:DeepSeek V4-Pro以1.6T参数和1M上下文窗口展现全能表现,MiniMax M2.5以80.2% SWE-bench得分和100TPS推理速度成为性价比之王,GLM-5.1以58.4% SWE-benchPro得分创开源纪录,Qwen3-Coder-30B专注代码生成,Kimi-K2擅长思维链推理,MiniMax M2.7强化多智能体协作能力。评测涵
本报告对当前主流AI大模型在纯文本理解场景下的性能进行系统评估,涵盖DeepSeekV4、GLM-5、Qwen3.5等10款模型。DeepSeekV4-Pro以1M上下文、88.7 MMLU得分成为开源天花板;GLM-5在AAIntelligenceIndex获50分,与ClaudeOpus4.5同级;Qwen3.5-397B以91.5 MMLU得分居开源第一。报告建议:追求性能选DeepSeek
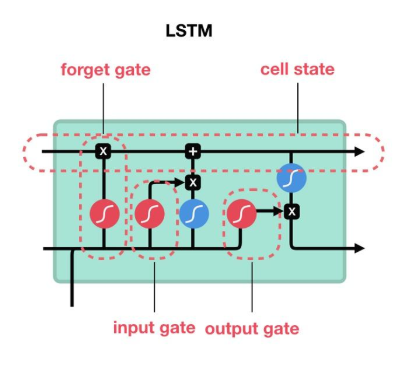
循环神经网络(RNN)为处理序列数据提供了基础框架,但其在长序列处理上的局限性促使了长短期记忆网络(LSTM)和门控循环单元(GRU)的诞生。LSTM 通过精细的门控机制和细胞状态,有效地解决了梯度问题,能够处理复杂的长序列数据。GRU 则在保持一定性能的同时,通过简化结构提高了训练效率。在实际应用中,我们需要根据具体任务的特点和需求,选择合适的模型。希望通过本文的介绍,你对 RNN、LSTM 和
2026年2月26日成为AI发展里程碑:中国AI模型调用量首次超越美国,全球前五模型中国占四席;可灵3.0登顶文生视频榜首,华为云码道上线,国产AI实现全维度突破。英伟达财报创纪录,Meta与AMD签600亿美元芯片订单,全球算力竞赛白热化。AI应用全面爆发,从消费到产业实现规模化落地,同时全球监管收紧,安全伦理成为焦点。这一天标志着中国AI从追赶到领跑、行业从技术竞赛转向应用落地、发展模式从野蛮

本文系统解析了AIAgent工程化的三代技术演进。第一代Prompt Engineering通过优化提示词解决基础交互问题;第二代Context Engineering通过上下文管理解决信息边界问题;第三代Harness Engineering构建完整工程框架,实现任务规划、执行评估和安全管控的三层闭环架构。文章详细阐述了三代技术的核心方法、适用场景及相互关系,并分享了全球大厂的成功案例。

Ollama 是一个开源的本地化大模型运行平台,支持用户直接在个人计算机上部署、管理和交互大型语言模型(LLMs),无需依赖云端服务。而且其混合推理的特性也使得CPU和GPU的算力能够充分被使用,能够在同等配置下跑更大的模型,是非常适合个人学习使用的平台。本篇将详细介绍Ollama在各种平台上的详细安装过程以及应用。
在之前的探索大语言模型(LLM):Ollama快速安装部署及使用(含Linux环境下离线安装)中,已经介绍了ollama在Windows环境下和Linux环境下的安装,在本篇中将重点介绍Ollama的常用配置
本报告对当前主流AI大模型在纯文本理解场景下的性能进行系统评估,涵盖DeepSeekV4、GLM-5、Qwen3.5等10款模型。DeepSeekV4-Pro以1M上下文、88.7 MMLU得分成为开源天花板;GLM-5在AAIntelligenceIndex获50分,与ClaudeOpus4.5同级;Qwen3.5-397B以91.5 MMLU得分居开源第一。报告建议:追求性能选DeepSeek
2026年主流编程大模型横向评测:DeepSeek V4-Pro以1.6T参数和1M上下文窗口展现全能表现,MiniMax M2.5以80.2% SWE-bench得分和100TPS推理速度成为性价比之王,GLM-5.1以58.4% SWE-benchPro得分创开源纪录,Qwen3-Coder-30B专注代码生成,Kimi-K2擅长思维链推理,MiniMax M2.7强化多智能体协作能力。评测涵