




- @Charmve
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
随着低代码(Low Code)和DevOps的推进,机器学习等的模型训练、部署全流程自动化技术、容器化技术的推广,逐渐可以做到计算机视觉MLOps。今天分享的文章就是介绍这样的一个工具链,帮助你完成模型训练、调参、monitor、部署的全流程自动化。L0CV项目主页 https://github.com/Charmve/computer-vision-in-action/tree/main/L0C
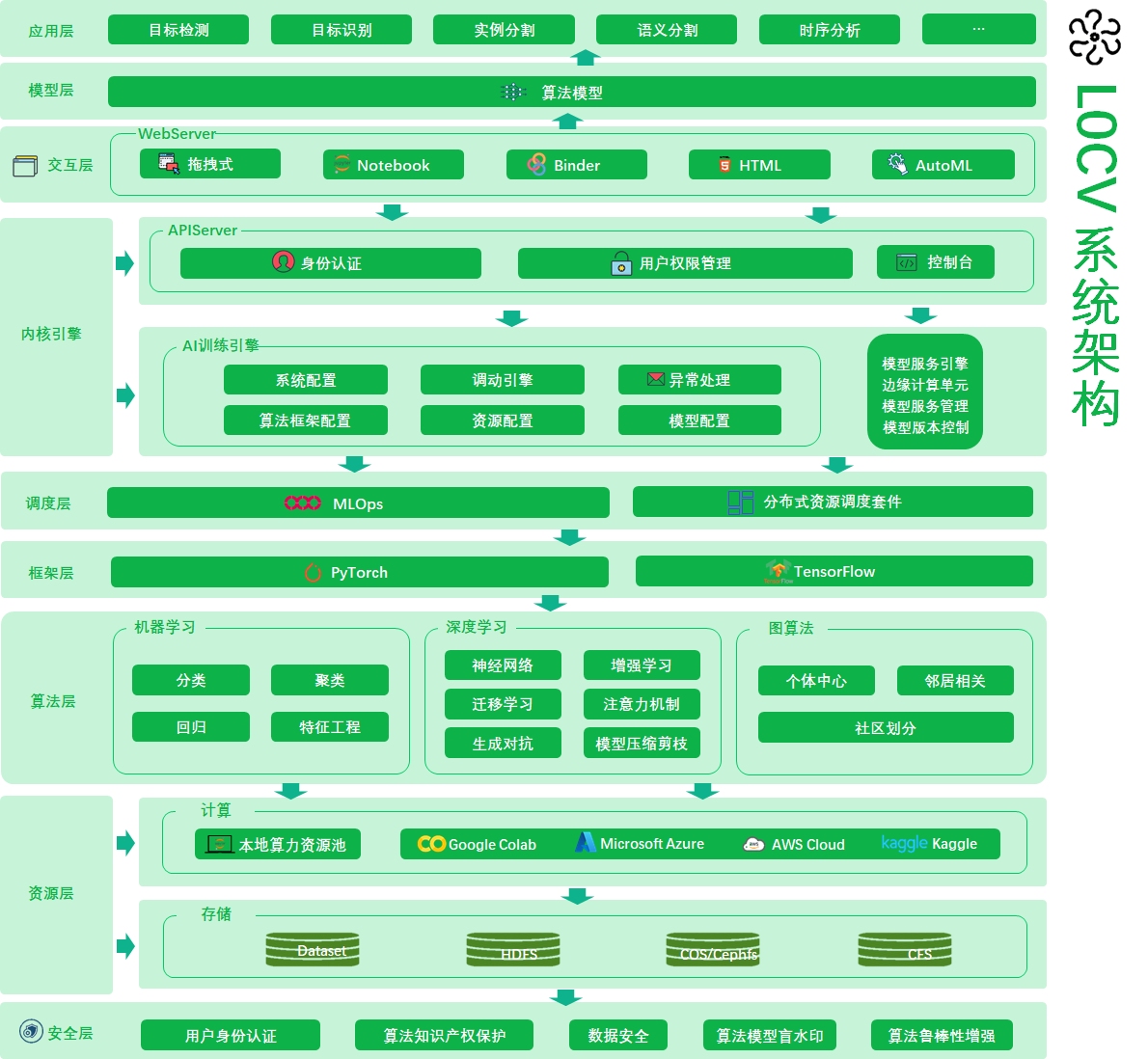
本学习资源以计算机视觉的发展历程和自顶向下的学习过程为核心,为读者提供一个 人人可学习计算机视觉的开放平台。我们围绕这样的组织逻辑:什么是计算机视觉?计算机视觉解决什么问题,都是怎么解决的?传统方法——以卷积神经网络为中心的神经网络;现代方法——Transformer、强化学习、迁移学习、生成对抗等。各种方法是如何实现的,用到了什么框架?在本资源中,这些问题都将会给予解决。
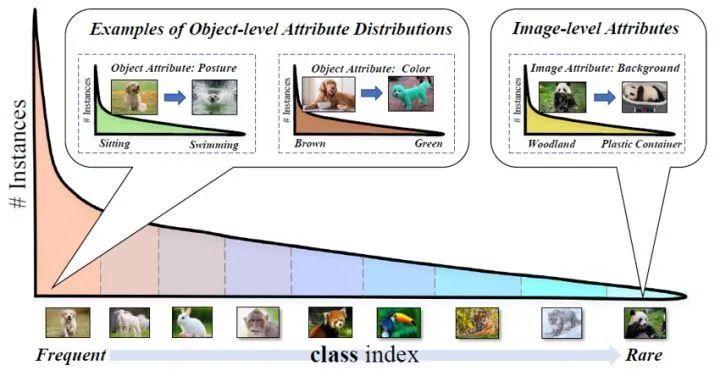
长尾分类领域最近的“进展”到底提升的是什么?长尾分布相关的问题后续还能不能做?该怎么做?细看本文作者为大家娓娓道来~时隔两年,饱受了社会的毒打之后,让我们再次重新回到计算机视觉中的长尾分布这个我博士期间研究的主要问题上,看看2022年了这个方向是否还值得继续做下去...
OpenAI 的 CLIP 模型在匹配图像与文本类别方面非常强大,但原始 CLIP 模型是在 4 亿多个图像 - 文本对上训练的,耗费了相当大的算力。来自 PicCollage 公司的研究者最近进行了缩小 CLIP 模型尺寸的研究,并取得了出色的效果。
本文提出将3D目标表示为点(points),表现SOTA!性能优于3DSSD、PointPainting等,端到端3D检测和跟踪速度达30 FPS!代码现已开源!
当前,卷积神经网络(CNN)和基于自注意力的网络(如近来大火的 ViT)是计算机视觉领域的主流选择,但研究人员没有停止探索视觉网络架构的脚步。近日,来自谷歌大脑的研究团队(原 ViT 团队)提出了一种舍弃卷积和自注意力且完全使用多层感知机(MLP)的视觉网络架构,在设计上非常简单,并且在 ImageNet 数据集上实现了媲美 CNN 和 ViT 的性能表现。
对于 Mac 用户来说,这是令人激动的一天。今年 3 月,苹果发布了其自研 M1 芯片的最终型号 M1 Ultra,它由 1140 亿个晶体管组成,是有史以来个人计算机中最大的数字。苹果宣称只需 1/3 的功耗,M1 Ultra 就可以实现比桌面级 GPU RTX ......

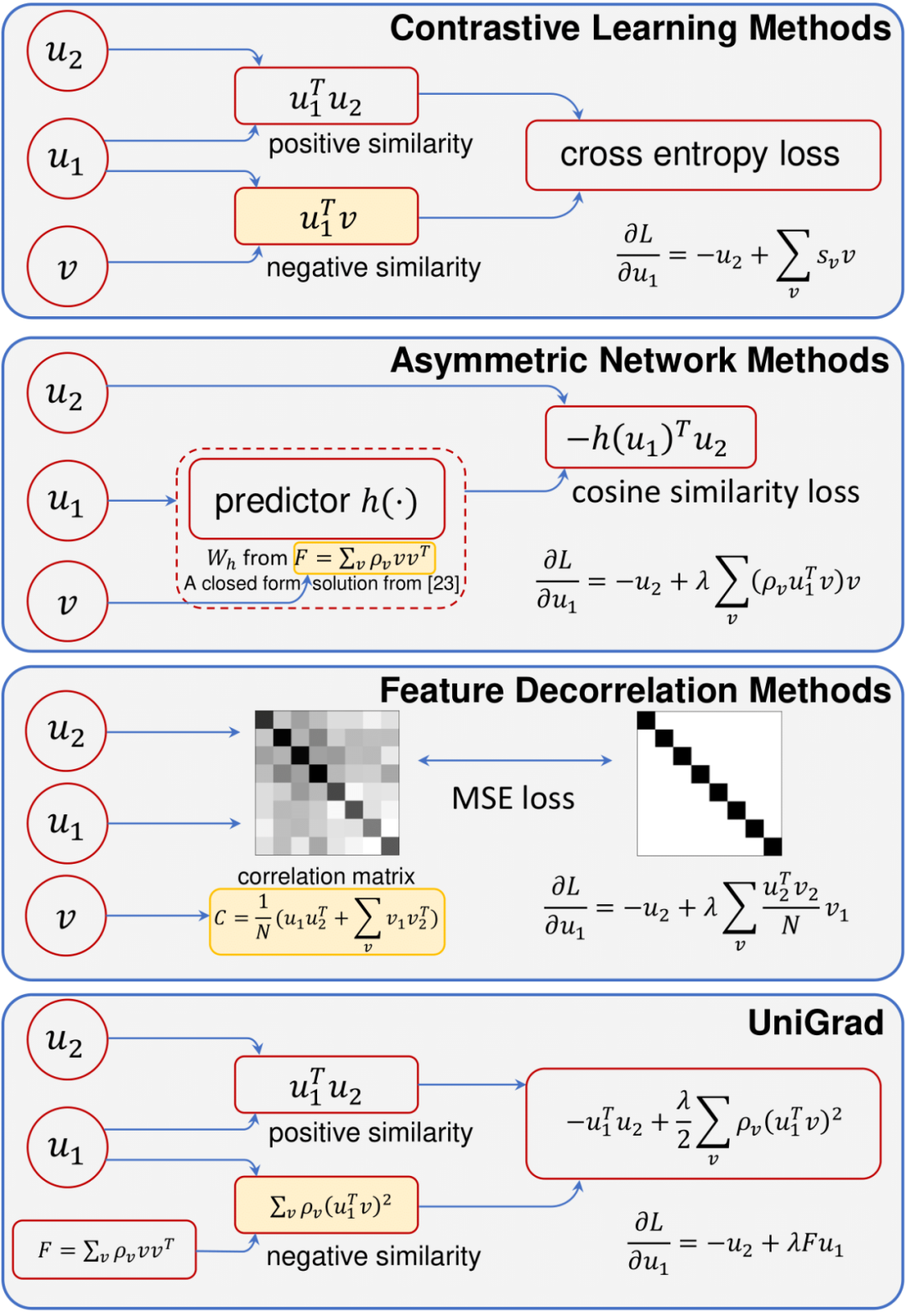
来自清华大学、商汤科技等机构的研究者们提出一种简洁而有效的梯度形式——UniGrad,不需要复杂的 memory ba...
点击上方“迈微AI研习社”,选择“星标★”公众号重磅干货,第一时间送达转载自:机器之心 | 作者:陈小康来自北京大学、香港大学和百度的研究者近日提出了一种名为CAE的新型 MIM 方法。掩码建模方法,在 NLP 领域 (例如 BERT) 得到了广泛的应用。随着 ViT 的提出和发展,人们也尝试将掩码图像建模(MIM)应用到视觉领域并取得了一定进展。在此之前,视觉自监督算...
Facebook新作MaskFeat,该工作的ViT-B在ImageNet 1K上的准确率达到了84.0%,MViT-L在Kinetics-400上的准确率达到了86.7%,一举超越了MAE,BEiT和SimMIM等方法。