
写文章




- @Ceverymxt7
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
python实现数字签名算法
【代码】python实现数字签名算法。

python爬虫入门——Selenium
如果你的学习方向和我一样是大模型,在模型微调的过程中必然需要大量的数据,学会使用爬虫会非常有用。如果你是做电商的或是正在求职,那么学会使用爬虫也能帮助你快速找到你需要的信息。 亦或者你学习爬虫是有其他需求,我也希望这篇文章能帮助完成它。
笔记:一些关于LLM的概念
本人在学习大模型过程中留下的一些笔记,希望对你有入门LLM有帮助。

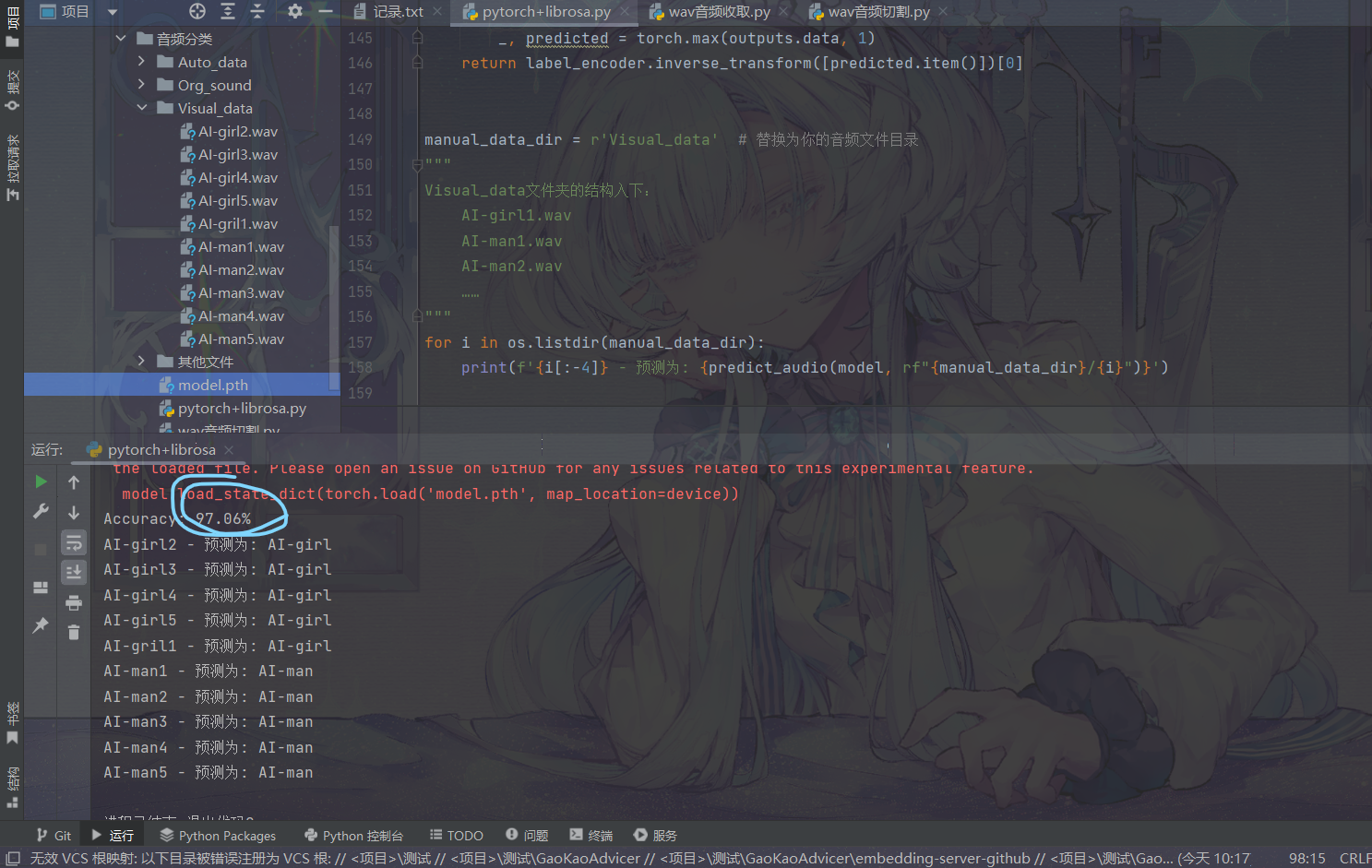
torch入门:音频分类任务(pytorch+librosa)
前面我们已经做过了一些文本分类任务,下面我们来试着完成一个音频分类任务吧。音频分类任务简单来说就是现在有若干个人说话时的音频数据,你需要使用这些数据来训练一个模型,能够分类好这些人的语音,当这些人当中的某人再次发言时,你的模型能够识别出是谁在说话。音频分类理论上来说完全可以用来分类歌曲,但是对于新手来说我建议您先从数据噪声较小的个人语音分类做起较好。
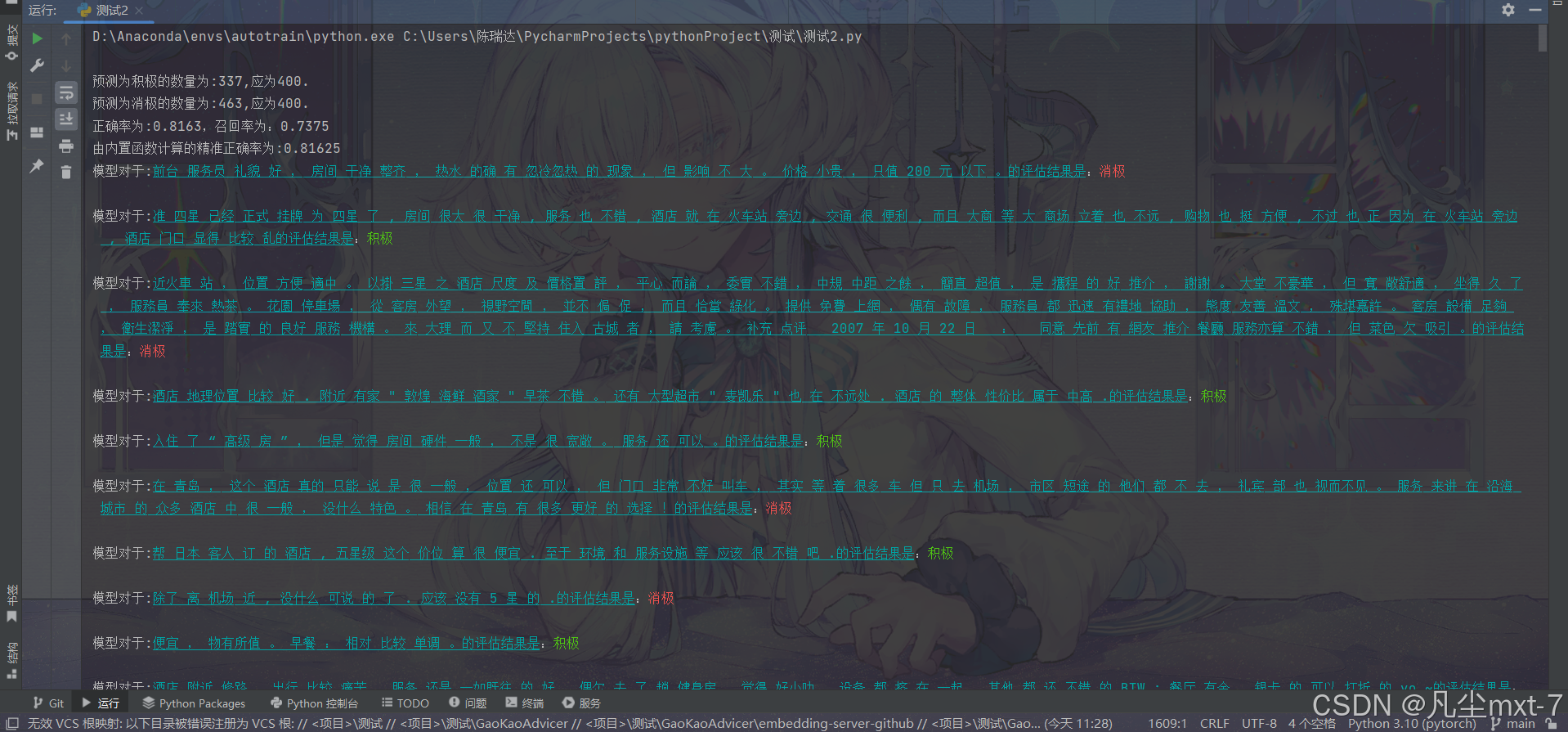
大模型入门:文本分类任务(基于fasttext与jieba)
本人认为将文本分类任务作为大模型的入门任务来说是不错的,因为这类任务的目的明确,数据获取较简单,模型回馈的结果明显,是很好的起点。 而“情绪分类”则是文本分类任务中的经典,我们下面就基于python的fasttext库与jieba分词器来完成一个“情绪分类”的任务。
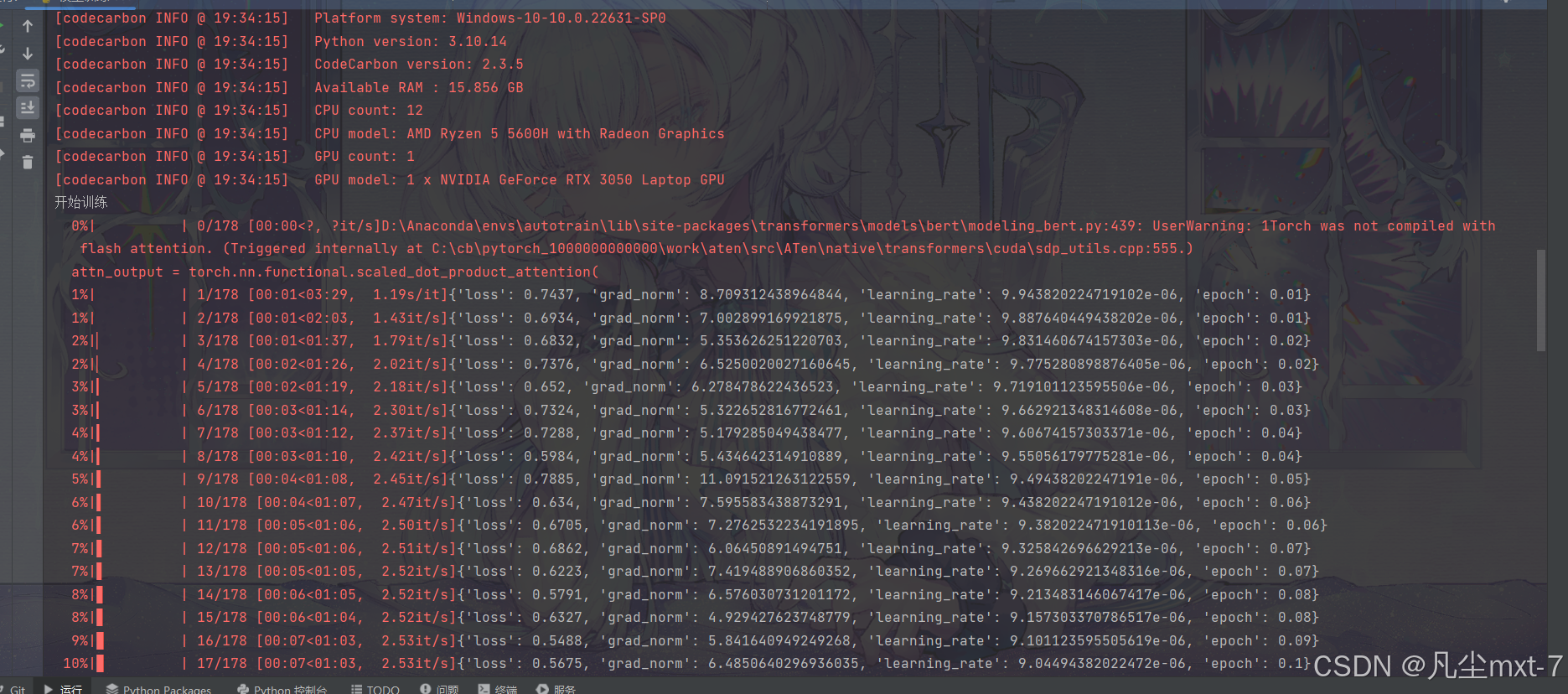
大模型入门:文本分类任务(基于Bert进行微调)
在上一篇文章中我介绍了如何通过fasttext来对文本进行分类,然而fasttext的训练过程非常短,对算力的需求很低,且对于参数的要求比较模糊,所以可能有朋友对模型的训练与迭代还是没有一个清晰的理解,下面我们换一种方法来对同样的文本进行分类任务,应该能让你对模型训练与微调有更加清晰的理解。
到底了