- @CXDNW
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
有一堆石头,用整数数组stones表示。其中stones[i]表示第i块石头的重量。每一回合,从中选出任意两块石头,然后将它们一起粉碎。假设石头的重量分别为x和y,且x <= y。那么粉碎的可能结果如下:如果x == y,那么两块石头都会被完全粉碎;如果x!= y,那么重量为x的石头将会完全粉碎,而重量为y的石头新重量为y-x。最后,最多只会剩下一块 石头。返回此石头 最小的可能重量。如果没有石头

如果想 表示 无向图,即:grid[2][5] = 6,grid[5][2] = 6,表示 节点 2 与 节点 5 相互连通,权值为6。用一个方格地图,假如每次搜索的方向为 上下左右(不包含斜上方),那么给出一个start起始位置,那么BFS就是从四个方向走出第一步。grid[2][5] = 6,表示 节点 2 连接 节点 5 为 有向图,节点 2 指向 节点 5,边的 权值为 6。然后我们再去遍

上图显示了一个 通用路由器 体系结构的 总体视图,其中 标识了一台 路由器的 4 个组件。第二层交换机 和 第三层路由器等 中间盒 剧增,而且 每种都有自己 特殊的 硬件、软件 和 管理界面,无疑 给许多网络操作员 带来了十分头疼的 大麻烦。然而,近期 软件定义 网络的 进展 已经预示 并且正在 提出一种统一的 方法,以一种现代、简洁和综合方式,提供 多种网络层功能 以及 某些 链路层功能。

Web 页面(Web page)(也叫文档)是由 对象 组成的。一个对象(object)只是一个文件,诸如一个 HTML 文件、一个 JPEG 图形、一个 Java 小程序或一个视频片段这样的文件,且它们可 通过一个 URL 地址 寻址。多数 Web 页面含有一个 HTML 基本文件(base HTMLfile)以及几个 引用对象。例如,如果一个 Web 页面包含 HTML 文本和 5 个JPEG

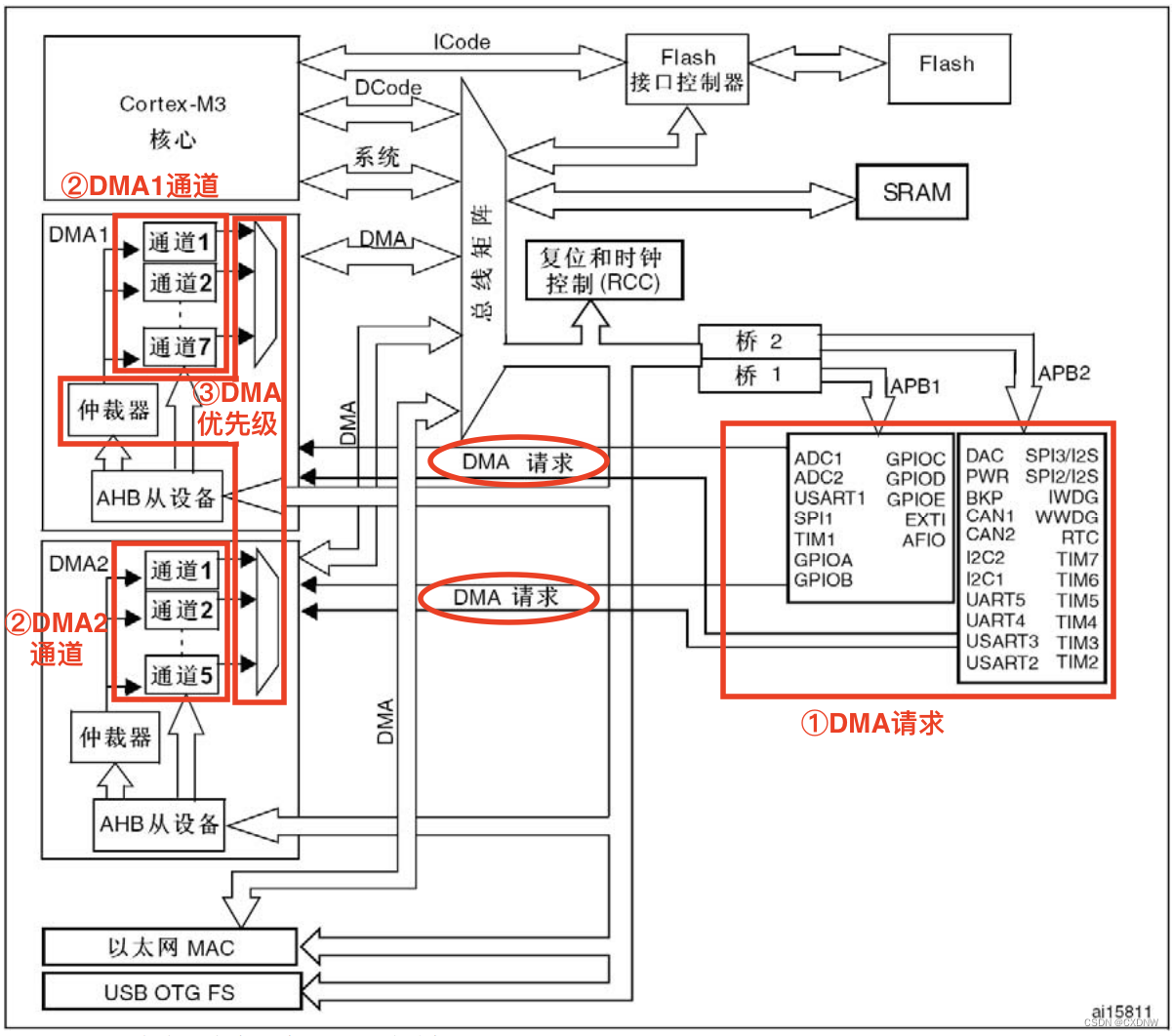
DMA,全称 Direct Memory Access,即直接存储器访问。用来提供在外设和存储器之间或者存储器和存储器之间的高速数据传输。DMA传输无需CPU直接控制传输,也没有中断处理方式那样保留现场和恢复现场过程,通过硬件为RAM和IO设备开辟一条直接传输数据的通道,使得CPU的效率大大提高。数据搬运工。
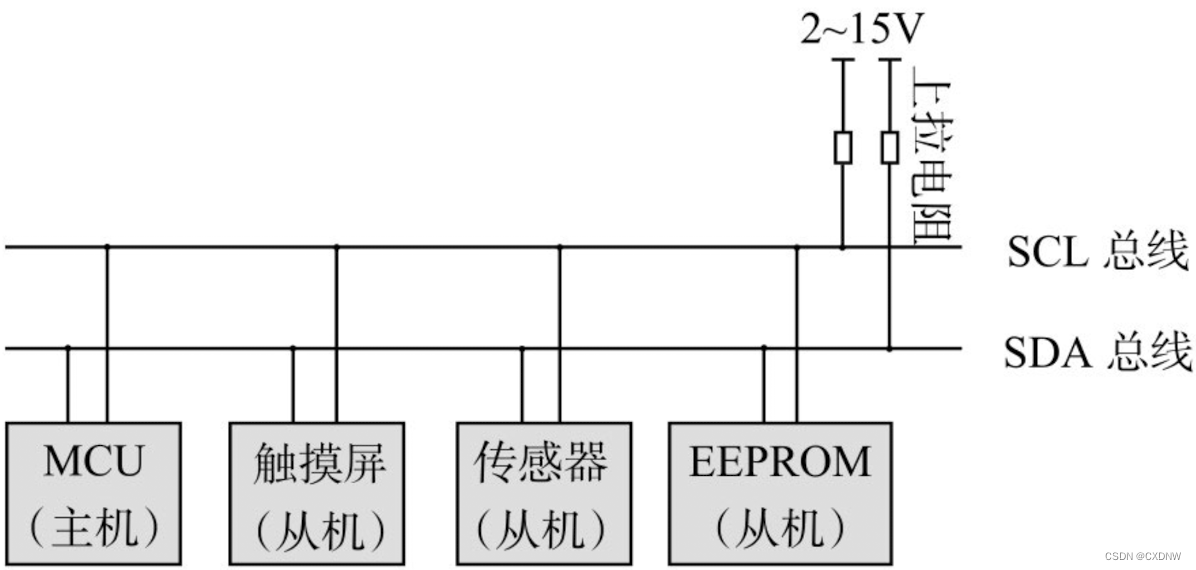
IIC通信协议是由Philips公司开发的,提供多主机功能,控制所有IIC总线特定的时序、协议、仲裁和定时。由于不需要使用USART、CAN等通信协议的外部收发设备,现在被广泛地用于系统内多个集成电路间的通信。
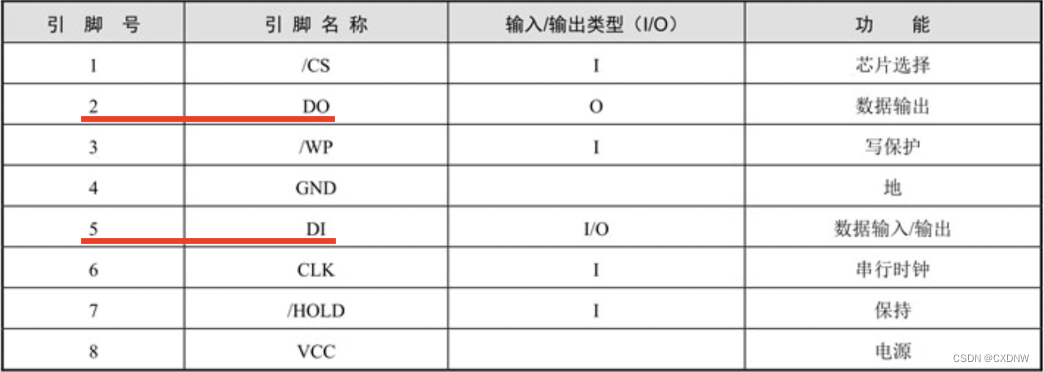
W25Q16、 W25Q32 和 W25Q64 支持标准的 SPl接口,传输速率最大 75 MHz,采用四线制,即4个引脚。① 串行 时钟引脚 (CLK)② 芯片 选择引脚 (CS)③ 串行数据 输出引脚(DO)④ 串行数据 输入 / 输出引脚(DIO):在普通情况下,该引脚是串行输入引脚(DI),当使用快读双输出指令时,该 引脚就变成了 输出引脚,在 这种情况下,芯片就有2个 DO引脚,所以称为
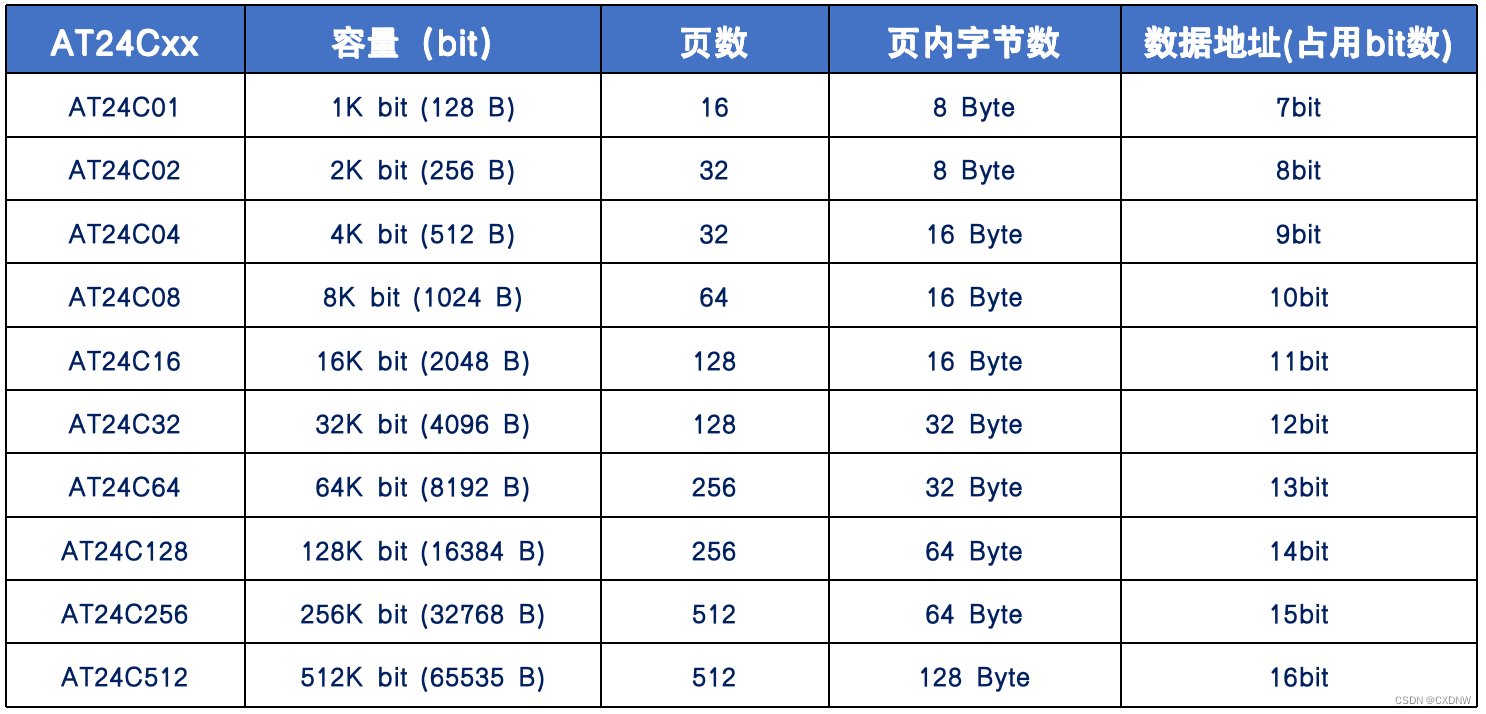
AT24C02是 低工作电压的 2Kb 串行电可擦除只读存储器,可存储256个字节数据,内部有一个16字节页写缓冲器。AT24C02工作电压 1.8~5.5V,采用二线制IIC数据传输协议,支持硬件写保护,能擦写 100万次,数据可保存 100年。通过器件地址输入端A0、A1和 A2可以实现将最多 8个 AT24C02器件 连接到 IIC总线上。补:EEPROM 是一种掉电后数据不丢失的储存器,常
算法得出的结论,永远不是 100% 确定的,更多的是判断出了一种 “ 样本的标签更可能是某类的可能性 ”,而非一种 “ 确定 ”。决策树 使用的 是 叶子节点上 占比较多 的标签 所占的比例(接口 predict_proba 调用),逻辑回归 使用的 是 sigmoid函数 压缩后的 似然(接口 predict_proba 调用),而 SVM 使用的 是样本点到 决策边界的 距离(接口 decis

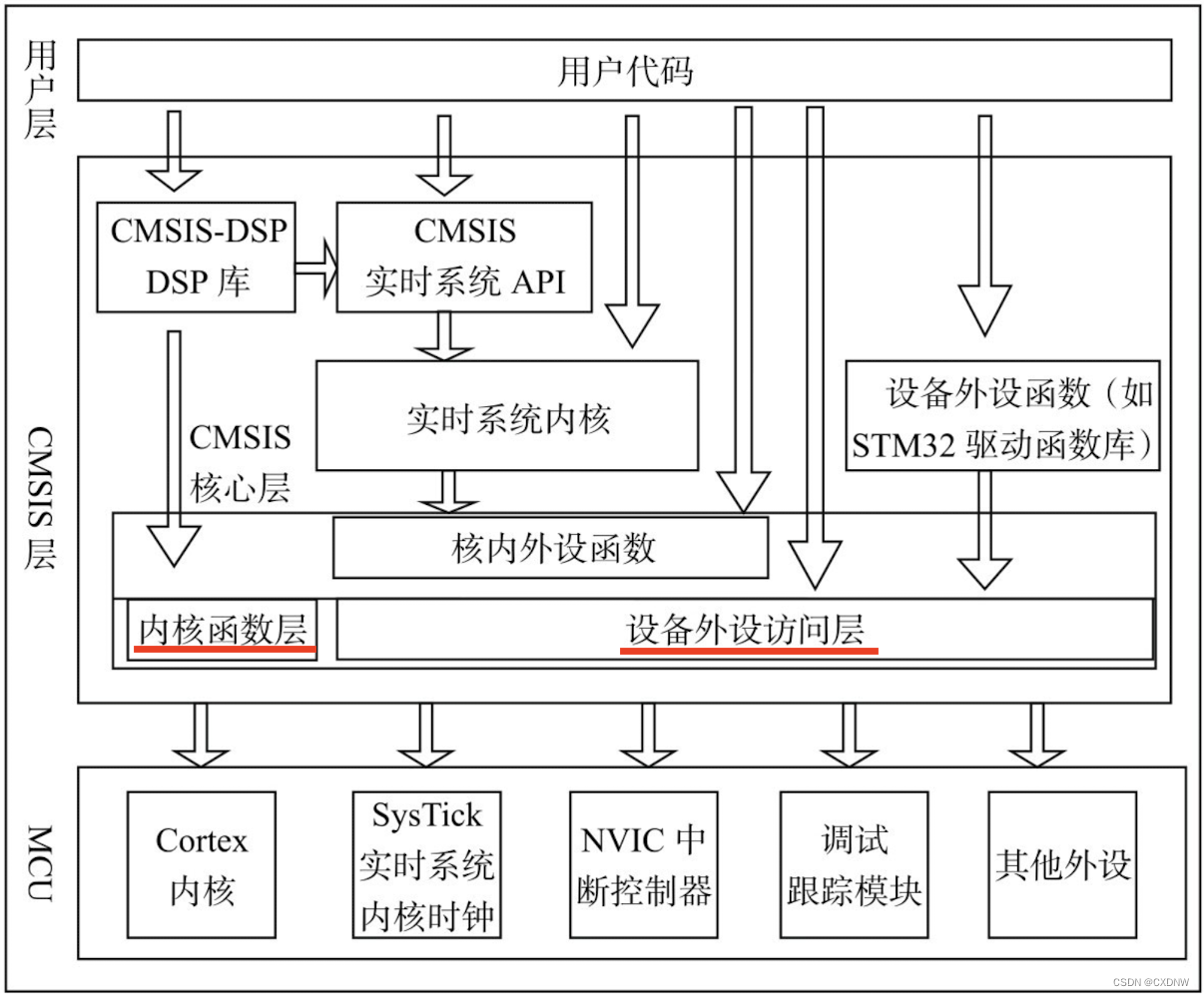
1)内核相关文件在CoreSupport文件夹中有 core_cm3.c和 core_cm3.h 两个文件。core_cm3.h头文件里面实现了内核的寄存器映射对应外设头文件 stm32f10x.h,区别就是一个针对内核的外设,一个针对片上(内核之外)的外设。core_cm3.c文件实现了操作内核外部寄存器的函数,用得比较少。2)启动文件启动文件放在startup/arm文件夹下,里面启动文件有很