- @CVHub
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文提出了模型,通过优化内存效率和注意力计算冗余,实现了高速且内存高效的视觉模型,并在实验中展示了它在速度和准确性方面的优越性能。此外,本文代码已开源,同时提供了转onnx等示例,提速非常明显,欢迎大家踊跃尝试!

是一款全新的交互式自动标注工具,其基于进行构建和二次开发,在此基础上扩展并支持了许多的模型和功能,并借助和YOLO等主流模型提供强大的 AI 支持。无须任何复杂配置,下载即用,支持自定义模型,极大提升用户标注效率!本文主要为大家介绍一款新颖实用的基于交互式的全自动标注工具——,更多功能和特性可直接下载体验!源码链接:https://github.com/CVHub520/X-AnyLabeling

参赛者需要根据传感器数据序列给出特定时间戳上的无人机位置数据并提交到赛事系统中,根据分类和预测精度得出最终的得分。比赛主要分为两个阶段 算法开发阶段(Dry-run)和最终验证阶段(Testing)。在算法开发阶段(Dry-run)挑战赛提供一个有标签训练集和一个无标签的开发用数据集,参赛者需要在这一阶段完成开发模型,测试结果提交格式等任务。在最终验证阶段(Testing),挑战赛会发布一个最终数

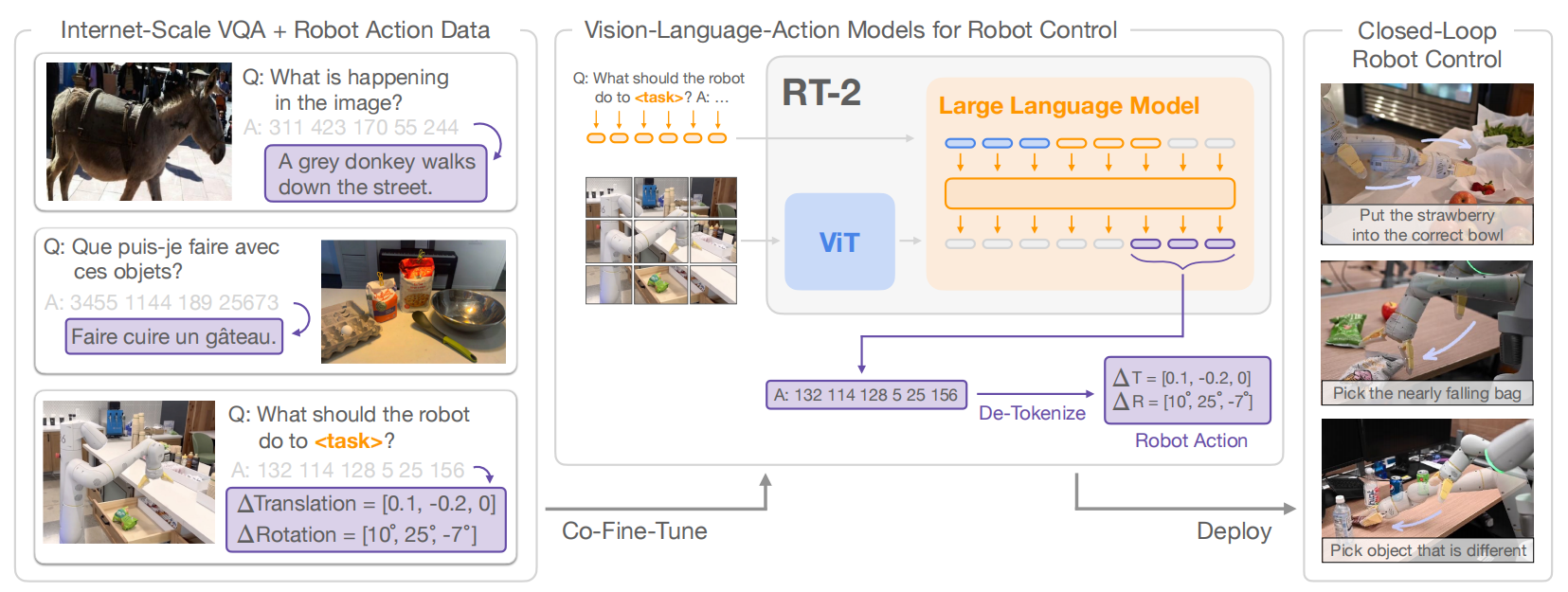
扯了这么多,那到底啥是机器人具身智能?是不是机器人长成人样的就是具身智能?回答是:否!具身具身,不是人形就表示具身,具身智能不是一定是人形机器人!!!只能说人形机器人是具身智能一个比较好的载体。具身的含义不是身体本身,而是与环境交互以及在环境中做事的整体需求和功能。按照上海交大卢策吾的举例,上图右上角有两只猫,一直猫被绑起来,只能看这个世界;另一只猫可以主动去走。被动的猫是一种旁观的智能,而主动的

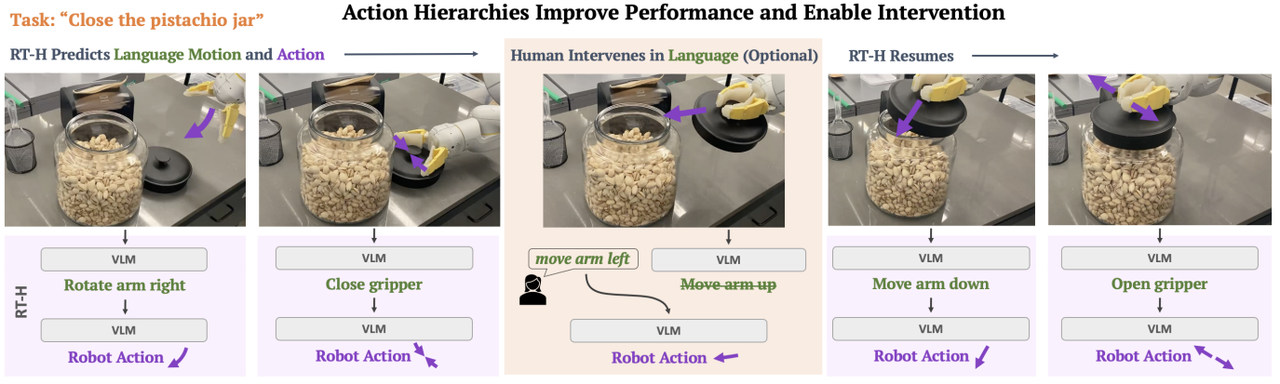
例如,如果机器人在拿起一个物体时动作不正确,人类可以输入新的指令,如“向左移动手臂”或“更慢地旋转手腕”,以纠正机器人的动作。RT-H在高层次任务描述(task descriptions)和低层次动作(action)之间引入一个中间层,即语言动作(language motions),这些语言动作是用更细粒度的短语来描述机器人的低级动作,例如“向前移动手臂”或“向右旋转手臂”。RT-H模型不仅可以响
X-AnyLabeling 是面向个人与中小团队的一站式多模态AI标注平台,基于纯Python生态,集成训练、推理与标注,架构高内聚低耦合,支持高度定制,致力于高效、灵活的真实场景应用。
是一款全新的交互式自动标注工具,其基于进行构建和二次开发,在此基础上扩展并支持了许多的模型和功能,并借助和YOLO等主流模型提供强大的 AI 支持。无须任何复杂配置,下载即用,支持自定义模型,极大提升用户标注效率!本文主要为大家介绍一款新颖实用的基于交互式的全自动标注工具——,更多功能和特性可直接下载体验!源码链接:https://github.com/CVHub520/X-AnyLabeling
申请邮箱:walter.wang@dji.com(坐标:深圳)邮箱主题:“姓名-社招/校招-岗位名称”(来信请务必附上。

扯了这么多,那到底啥是机器人具身智能?是不是机器人长成人样的就是具身智能?回答是:否!具身具身,不是人形就表示具身,具身智能不是一定是人形机器人!!!只能说人形机器人是具身智能一个比较好的载体。具身的含义不是身体本身,而是与环境交互以及在环境中做事的整体需求和功能。按照上海交大卢策吾的举例,上图右上角有两只猫,一直猫被绑起来,只能看这个世界;另一只猫可以主动去走。被动的猫是一种旁观的智能,而主动的