- @AI_gurubar
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
OpenAI 的官方介绍页面提供了 GPT-5 的概述,包括其主要特性和应用场景(OpenAIGPT-5 是 OpenAI 迄今为止最智能、最快速、最有用的模型,具备专家级的思维能力。支持多模态输入(文本、图像、视频、音频),在健康、编程、创作等领域表现出色(如下图)。MultimodalCodingGPT-5 被广泛认为是 OpenAI 在人工智能领域的重要进展,尤其在编码、推理和健康领域表现出

尽管有Coltraro等人的研究评估并改进了模拟器逼真度。

模型崩溃”指的是在生成式模型训练中,不断使用模型自身或其他模型生成的内容作为训练数据,导致模型逐代偏离真实数据分布,从而引发性能退化的问题(维基百科IBMShumailov 等人在《Nature》对该现象进行了系统描述,并指出其由三种误差累计导致: 统计近似误差(sampling error) , 功能表达误差(functional expressivity error) , 学习误差(learn

OpenAI 的 gpt-oss 模型系列在技术架构、性能、安全性和开放生态等方面均具有重要意义:架构创新:采用 MoE 架构和高效的训练技术,提高了模型的计算效率。性能提升:在多个标准基准测试中表现优异,适用于多种应用场景。安全防范:通过严格的安全评估和机制设计,降低了模型被滥用的风险。开放生态:通过开放许可证和多平台支持,促进了 AI 技术的广泛应用。这一发布标志着 OpenAI 在开放 AI

Jason Wei 曾任职于 Google Brain(2020–2023),其间主导或参与了多项影响深远的研究工作,包括:Chain‑of‑Thought(思维链)Prompting:提出通过在提示中加入“chain-of-thought”示例,使大模型展现分步推理能力,从而在算术、常识推理和符号操作等任务上达到更高表现 (arXiv同时,Jason Wei 对 self-consistency

2025年Google DeepMind与OpenAI先后宣布其AI系统在IMO测试中达到了“金牌”级别的表现。DeepMind的Gemini Deep Think模型通过与IMO官方合作,正式获得金牌认证,而OpenAI则基于内部评估和独立数学专家的判定宣称其实验性推理模型也达到了金牌水平。这两起事件标志着AI在高难度数学推理领域的显著突破,预示着AI与人类数学家在未来有望展开更深层次的合作与竞

每部分都配一句 insight,一个信息流示意图(便于理解),并且按。
1995 年,Stephen Thaler 展示了人工神经网络在连接权重随机扰动下如何产生幻觉和幻影体验Edu。作者构建了一个简单的 3–5–9 前馈模式联想器: 输入层:3 个节点(可表示 8 种三位二进制模式);隐藏层:5 个节点;输出层:9 个节点,对应 3×3 的像素图案。训练任务是: 每个三位输入模式 → 一个对称的 3×3 输出像素图案(如下所示):实验的关键步骤是随机剪枝连接权重,也

过去两年,视频生成模型从「好看」逐步走向「可用」。Genie 3 把这一趋势推到台前:它能把文本或图像提示转成可实时交互的 3D 世界,以 720p/24 fps 持续运行数分钟,并支持“可提示的世界事件”(如改变天气、加入角色),同时维持较强的对象与场景记忆一致性,虽仍处于限量研究预览阶段,但已明确展示了从被动视频到可控世界模拟器(即世界模型,World Model)的跃迁。Genie 3。
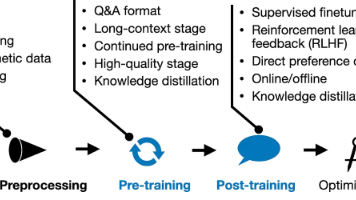
综上,2024 年以来 LLM 后训练技术在对齐和优化上取得了长足进展。一方面,新型强化学习范式(如 RLSF、AfD、迭代 DPO)摆脱了对人工偏好的完全依赖,探索了模型自我反馈和高效偏好优化的途径,为提升模型对齐性提供了更经济可扩展的方案。另一方面,围绕推理能力的专门训练使模型在复杂推理和多轮对话中表现出更强的一致性和准确性(通过显式或隐式的链式思维训练,以及引入逆向推理、注意力奖励等创新技术