




- @2501_93508870
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
道路病害(裂缝与坑槽)的自动化检测是智能交通与基础设施维护的核心难题。传统人工巡检效率低、主观性强,难以满足大规模路网需求。近年来,基于深度学习的视觉方法成为主流,但仍面临复杂背景干扰、小目标识别难、实时性要求高等挑战。本次解析的两篇论文分别从与两个方向探索解决方案:第一篇基于改进YOLOv8,引入ECA与CBAM双重注意力模块,显著提升裂缝分割精度;第二篇依托SHREC 2022国际竞赛,系统对

最近经常有朋友问我,想入门深度学习,到底该如何高效学习?作为一个过来人,我总结了一条非常实用的学习路径,。

卷积就是用一个“可移动的小窗口”(叫数据窗口),和图像逐元素相乘再相加的操作。这个小窗口其实是卷积核(滤波器),里面是一组固定权重,就像“特征探测器”,帮网络提取图像特征(比如边缘、纹理)。就像人眼先看轮廓再看细节,CNN通过卷积,能一步步“看到”图像的特征——比如第一层卷积可能提取出图像的边缘,后面的卷积层能提取出物体的局部结构,最后组合成完整的物体特征~

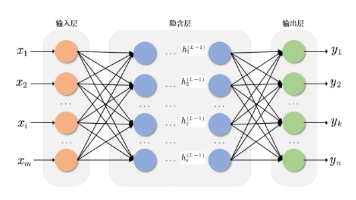
结构:输入→隐藏→输出,每层靠神经元(加权+激活)处理;流程:前向算预测→误差算对错→反向调参数(梯度下降);工具:不用死磕数学,先跑通简单代码(比如上面的Python示例),再慢慢理解细节。神经网络没那么玄乎,入门先抓“分层”“加权”“梯度下降”这3个核心,后续再学CNN(图像)、RNN(文本)就顺理成章啦!
Attention机制的核心就是“找重点、加权整合”,记住3个关键词(Q/K/V)和5步计算流程,再跑通代码,你就已经入门啦!如果想深入,下一步可以学习Transformer结构(毕竟“Attention is All You Need”就是Transformer的论文标题),后续会继续更新~

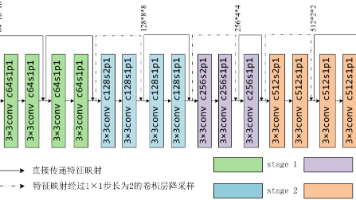
想做手机APP、智能手表上的图像识别:选MobileNet;想在服务器上快速得到高精度结果:选EfficientNet;刚入门CNN,想理解深层网络原理:选ResNet;只有少量数据,想让模型充分利用特征:选DenseNet。ResNet、DenseNet、EfficientNet、MobileNet四大模型,分别从“深度扩展”“特征重用”“效率平衡”“轻量化”四个角度解决了传统CNN的痛点,构成
首次投稿→CAIBDA/ACML(C类,熟悉流程)→1-2次修改后投ECML-PKDD(B类,积累成果)→有核心创新后冲击ICLR/CVPR(A类)」,通常需要1-2年周期,稳扎稳打更易建立科研信心。对于深度学习/机器学习方向的新人,建议从C类会议入手熟悉投稿流程,再逐步冲击更高层级会议。1-3月是ICML、ACL等顶会截止高峰,新人可优先选择7-12月截止的C类会议(如ACML、CAIBDA),
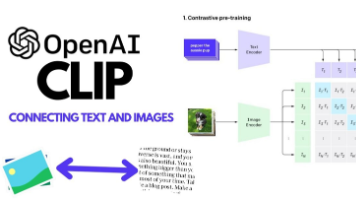
CLIP的核心不是“复杂公式”,而是“让图文学会对话”的简单逻辑。今天这个手写数字项目,从原理到代码都做到了“小白友好”——零数据下载、零环境踩坑、服务器自动保存结果图,10分钟就能跑通。多模态入门不用怕,跟着这个项目练一遍,你就已经掌握了CLIP的核心玩法!
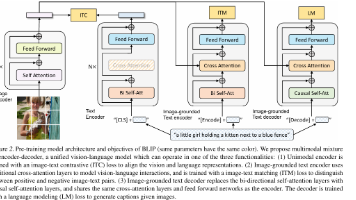
四大多模态模型代表了“从基础到进阶”的技术演进:BLIP奠定了图文对齐的基础,BLIP-2通过Q-Former实现了与LLM的高效融合,GPT-4V将图文推理能力推向顶峰,Gemini Pro则以统一架构降低了多模态部署门槛。通过本文的原理推导、公式解析和零门槛实操项目,相信你已经掌握了多模态模型的核心逻辑。不妨从API调用(Gemini Pro)开始,快速感受多模态的魅力,再逐步尝试本地部署BL
道路病害(裂缝与坑槽)的自动化检测是智能交通与基础设施维护的核心难题。传统人工巡检效率低、主观性强,难以满足大规模路网需求。近年来,基于深度学习的视觉方法成为主流,但仍面临复杂背景干扰、小目标识别难、实时性要求高等挑战。本次解析的两篇论文分别从与两个方向探索解决方案:第一篇基于改进YOLOv8,引入ECA与CBAM双重注意力模块,显著提升裂缝分割精度;第二篇依托SHREC 2022国际竞赛,系统对