




- @2501_92553370
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
面向强化学习的状态空间建模:RSSM的介绍和PyTorch实现(2)三、RSSM 整体架构。
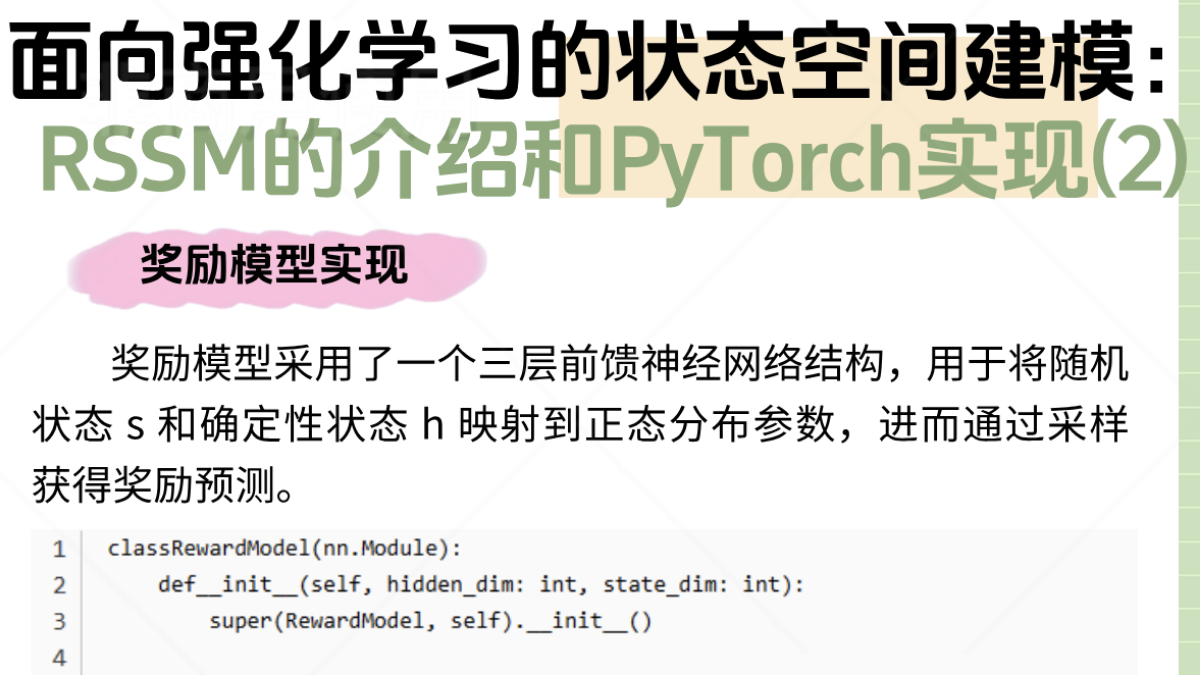
人工智能#具身智能#VLA#大模型#AI#LLM#Transformer 架构#AI技术前沿#Agent大模型#工信部证书#人工智能证书#职业证书。DNN案例一步步构建深层神经网络。二、应用的包import。一、总体目标与大致结构。

面向强化学习的状态空间建模:RSSM的介绍和PyTorch实现(3)面向强化学习的状态空间建模:RSSM的介绍和PyTorch实现(3)一、RSSM 整体架构。三、经验回放缓冲区实现。

Transformer是一种基于自注意力机制(Self-Attention)的神经网络架构,最早是在2017年由谷歌大脑团队Ashish Vaswani和多伦多大学的一个团队发表的一篇名为"Attention is All You Need"的论文中描述的。与传统的循环神经网络(RNN)不同,Transformer能够并行处理序列中的所有位置,通过注意力权重矩阵捕获任意距离的依赖关系。其中,编码组

三、如何找到 LoRA 模型。二、深入剖析LoRA 模型。大模型-LORA模型详解。四、如何使用 LoRA?

人工智能#具身智能#VLA#大模型#AI#LLM。4.向量数据的应用-RAG技术。1.为什么需要向量数据库。向量数据库拥抱大模型。

3.2 可学习的嵌入 (Learnable Embedding)大模型-详解 Vision Transformer (ViT)3.3 位置嵌入 (Position Embeddings)3.1 图像块嵌入 (Patch Embeddings)3.4 Transformer 编码器。3.5 ViT 张量维度变化举例。3.6 归纳偏置与混合架构。3.7 微调及更高分辨率。

人工智能#具身智能#VLA#大模型#AI。DNN案例一步步构建深层神经网络(3)四、对于构建的深层神经网络的应用。
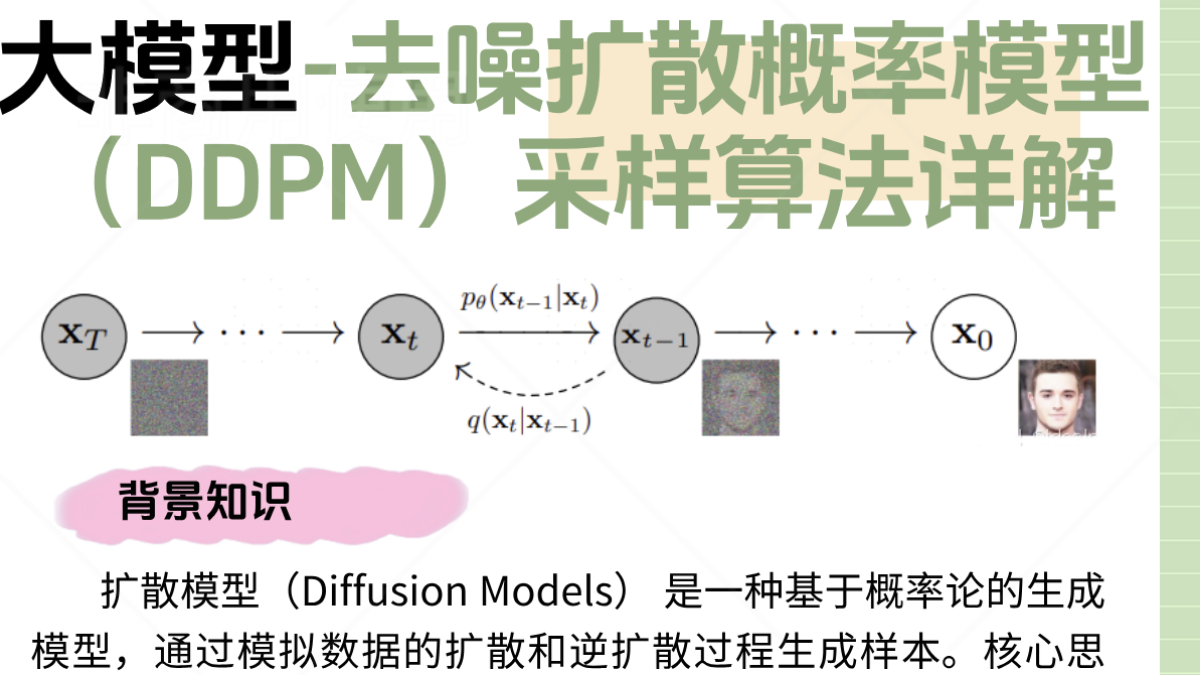
大模型-去噪扩散概率模型(DDPM)采样算法详解。任意时刻 ( x_t ) 的闭式解。
具身智能-普通LLM智能体与具身智能:从语言理解到自主行动。示例:中国企业中普通LLM智能体的应用——智能客服系统。人工智能/具身智能/VLA/大模型/AI。一、普通LLM智能体的本质。二、普通LLM智能体的应用。
