




- @2501_92499985
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Matplotlib 是 Python 提供的一个绘图库,通过该库我们可以很容易的绘制出折线图、直方图、散点图、饼图等丰富的统计图,安装使用命令即可,Matplotlib 经常会与NumPy一起使用。在进行数据分析时,可视化工作是一个十分重要的环节,数据可视化可以让我们更加直观、清晰的了解数据,Matplotlib 就是一种可视化实现方式。

NumPy(Numerical Python)是一个开源的 Python 科学计算扩展库,主要用来处理任意维度数组与矩阵,通常对于相同的计算任务,使用 NumPy 要比直接使用 Python 基本数据结构要简单、高效的多。安装使用命令即可。

我们在上一篇文章初识 Pandas中已经对 Pandas 作了一些基本介绍,本文我们进一步来学习 Pandas 的一些使用。

动态渲染能力:通过Selenium破解90%的JavaScript依赖网站分布式架构:单集群支持500+并发爬虫实例云原生特性:资源利用率提升400%,运维成本降低70%

你是都在先每次创建一个文件,开头都是如下?自定义脚本开头在 Python 中,当你给它赋值时就会创建变量:Python 没有用于声明变量的命令。变量在您第一次为其赋值时创建。1.x =52.y ="川川"3.print(x)4.print(y)1.x = 4# x 现在是整形2.x ="川川"# x 现在是字符串3.print(x)则打印为:1.

fill:#333;color:#333;color:#333;fill:none;合格不合格原始数据数据清洗数据质量评估特征工程模型训练异常检测人工复核规则优化。

fill:#333;color:#333;color:#333;fill:none;合格不合格原始数据数据清洗数据质量评估特征工程模型训练异常检测人工复核规则优化。
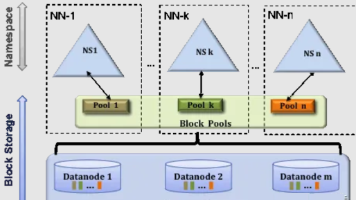
不同应用可以使用不同NameNode进行数据管理,比如日志分析业务、图片业务、爬虫业务等,不同的业务模块使用不同的NameNode进行管。理NameSpace。
地理穿透能力:通过全球代理节点实现精准地域访问系统健壮性:代理池自动维护机制保障99.9%可用率采集效率:分布式架构实现日均千万级URL处理成本优化:智能代理分级使有效IP利用率提升40%

你是都在先每次创建一个文件,开头都是如下?自定义脚本开头在 Python 中,当你给它赋值时就会创建变量:Python 没有用于声明变量的命令。变量在您第一次为其赋值时创建。1.x =52.y ="川川"3.print(x)4.print(y)1.x = 4# x 现在是整形2.x ="川川"# x 现在是字符串3.print(x)则打印为:1.