- @2401_88055648
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
最近在几个AI工具论坛和B站刷到不少人在聊MOSS-TTS-Nano,说是不用显卡靠CPU就能实时出声音,还能克隆音色。之前折腾过好几个语音克隆工具,基本都卡在显卡这一关,没有N卡或者显存不够就直接劝退。这次专门去查了官方仓库和几个UP主的实测记录,把看到的信息整理了一下,写给同样没有独立显卡、又想试试语音克隆的人看看。
在很多 TTS 系统里,情绪和音色是耦合的:改情绪往往也会改变音色。为了在强情绪表达下保证清晰度,模型还引入了 GPT 潜在表示(latent)辅助机制,并采用分阶段训练策略来稳定输出。这意味着你不需要采集大量语音,也无需专属模型,只要你有一段清晰的声音录音,就可以做“声音代入”。只要你的机器满足上述最低条件,再使用上述优化策略,就有可能在普通环境下跑通。这样,你可以用同一个人的音色做出不同情绪的
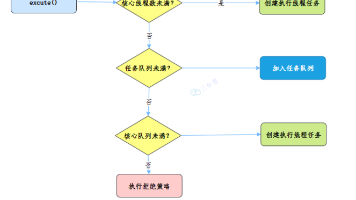
简单说,线程池就是提前创建好一批线程,然后让这些线程重复利用,去执行各种任务,而不是每次来一个任务就新建一个线程。你可以把线程池想象成一个工厂里的“工人队伍”。没有线程池之前:每来一个订单(任务),工厂就临时去外面招一个工人(创建线程)。订单完成后,这个工人就被辞退(销毁线程)。有了线程池之后:工厂里一直养着一支固定的工人队伍(线程池)。来订单了,就从队伍里拉一个闲着的工人去做;订单做完了,这个工
简单来说,Soundify Vocal Remover 就是一个跑在电脑本地的软件,专门干“拆歌”这以件事的。你给它一首完整的歌,它能利用 AI 算法,把里面的人声唱词和背后的乐器伴奏给劈开,生成两个独立的文件。最重要的一点是隐私和安全。它是完全离线运行的。我不喜欢把自己的文件传到别人的服务器上,谁知道对面会不会保存。用这个软件,不管你是处理自己录的私密语音,还是处理一些版权素材,文件从头到尾都在

前段时间刷到有人说美团旗下团队做了个 AI 浏览器,叫 Tabbit,可以免费用 GPT-5.4 和 Claude。我当时没太当回事,毕竟现在 AI 浏览器插件一堆,大多数就是在侧边栏嵌一个 ChatGPT 窗口,换个壳收你钱。但装上用了两周之后,发现它跟我想的不太一样。写下来给有需要的人参考一下。
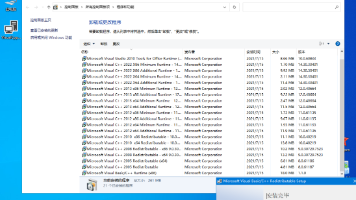
电脑上装游戏或者装软件,弹出一个窗口说"找不到 msvcp140.dll"或者"缺少 vcruntime140.dll",这种事估计不少人都碰到过。网上搜一圈,有人让你单独下载某个dll文件丢到系统目录里,有人让你装某个版本的 Visual C++。折腾半天,这个dll的问题解决了,下次又冒出另一个dll缺失。这篇文章介绍的 Visual C++运行库合集 v105.0,就是把微软历年来发布的所有
装完系统找驱动是个麻烦事,尤其是一些老机器或者小众硬件,官网驱动要么难找要么下载慢,用系统自带的更新又经常缺东少西。最近在几个常逛的论坛看到不少人在提 DriverEasy 这个软件,说是出了个魔改版本,把付费限制和广告全去掉了,试了下的确省心,顺便把使用过程整理出来。
这一轮封号潮背后,说到底是大公司之间的博弈牵连到了普通用户。个人能做的有限,无非是把账号申诉走一遍,同时手里备一个可以顶上的替代方案,不要把所有工作流程都吊在一个账号上。至于网上那些没有实锤的技术细节,看看就好,别当成板上钉钉的结论去传。

4月初,谷歌 DeepMind 悄悄把 Gemma 4 系列模型挂上了 HuggingFace,没有大张旗鼓,但社区反应很快——有人拉了一晚上的权重,有人直接开测,有人说这是今年到目前开源模型里最值得跑一遍的东西。这篇文章把这几天能找到的测试数据和部署方法整理了一下,给有兴趣自己跑跑看的朋友参考。

做后端或者运维的,平时要连的数据库可能不止一种。MySQL 用 Navicat,Redis 用 RedisInsight,MongoDB 专门开 Compass,有时候再加个 DBeaver 处理 PostgreSQL。几个工具来回切换,电脑内存吃了大半,每次切换还要重新找之前的查询窗口,挺烦的。最近遇到一个开源工具叫 DBX,GitHub 上已经有两千多个 Star,使用rust编写的,用了一段