




- @2401_84587944
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
我们已经加速进入了大模型的时代。以ChatGPT为首的一些超强模型服务,背后是百亿或千亿参数的基础模型,它们学到了丰富的世界知识,领悟了“与人类打交道”的门路,甚至开始连接和使用外部工具、成为“万物接口”。新的时代有新的机会,与其担心AI将取代我们的工作,不如学会驾驭它!不远的未来,AI大模型或许将是人人可用、人人可开发。本期大牛书单,我们请来了几位鹅厂同事,为大家推荐一些大模型相关的书籍文献和学

随着专家们暗示大型语言模型(LLM)的技术极限即将到来,人们的焦点转向了检索增强生成(RAG)——这是一项很有前途的进步,可以通过将信息检索与自然语言生成相结合来重新定义人工智能(AI)。LLM引领了人工智能技术,并改进了各种应用。然而,他们产生虚假信息的倾向限制了他们的潜力。RAG 允许 AI 访问特定的外部数据并将其纳入其响应中,使其更加有效和准确。
北京市委市政府高度重视人工智能发展,2023年5月,北京市政府印发《北京市加快建设具有全球影响力的人工智能创新策源地实施方案(2023-2025年)》,强调构建高效协同的大模型技术产业生态,建设大模型算法及工具开源开放平台,构建完整大模型技术创新体系。北京市政府办公厅印发《北京市促进通用人工智能创新发展的若干措施》,强调开展大模型创新算法及关键技术研究、加强大模型训练数据采集及治理工具研发,推动大

随着专家们暗示大型语言模型(LLM)的技术极限即将到来,人们的焦点转向了检索增强生成(RAG)——这是一项很有前途的进步,可以通过将信息检索与自然语言生成相结合来重新定义人工智能(AI)。LLM引领了人工智能技术,并改进了各种应用。然而,他们产生虚假信息的倾向限制了他们的潜力。RAG 允许 AI 访问特定的外部数据并将其纳入其响应中,使其更加有效和准确。
在当今快速发展的人工智能领域,国产技术正不断取得突破性进展。最近,由元象公司推出的XVERSE-V多模态大模型,以其卓越的性能和开放的商业模式,引起了业界的广泛关注。

我们已经加速进入了大模型的时代。以ChatGPT为首的一些超强模型服务,背后是百亿或千亿参数的基础模型,它们学到了丰富的世界知识,领悟了“与人类打交道”的门路,甚至开始连接和使用外部工具、成为“万物接口”。新的时代有新的机会,与其担心AI将取代我们的工作,不如学会驾驭它!不远的未来,AI大模型或许将是人人可用、人人可开发。本期大牛书单,我们请来了几位鹅厂同事,为大家推荐一些大模型相关的书籍文献和学
在当今快速发展的人工智能领域,国产技术正不断取得突破性进展。最近,由元象公司推出的XVERSE-V多模态大模型,以其卓越的性能和开放的商业模式,引起了业界的广泛关注。
链接:https://huggingface.co/meta-llama。

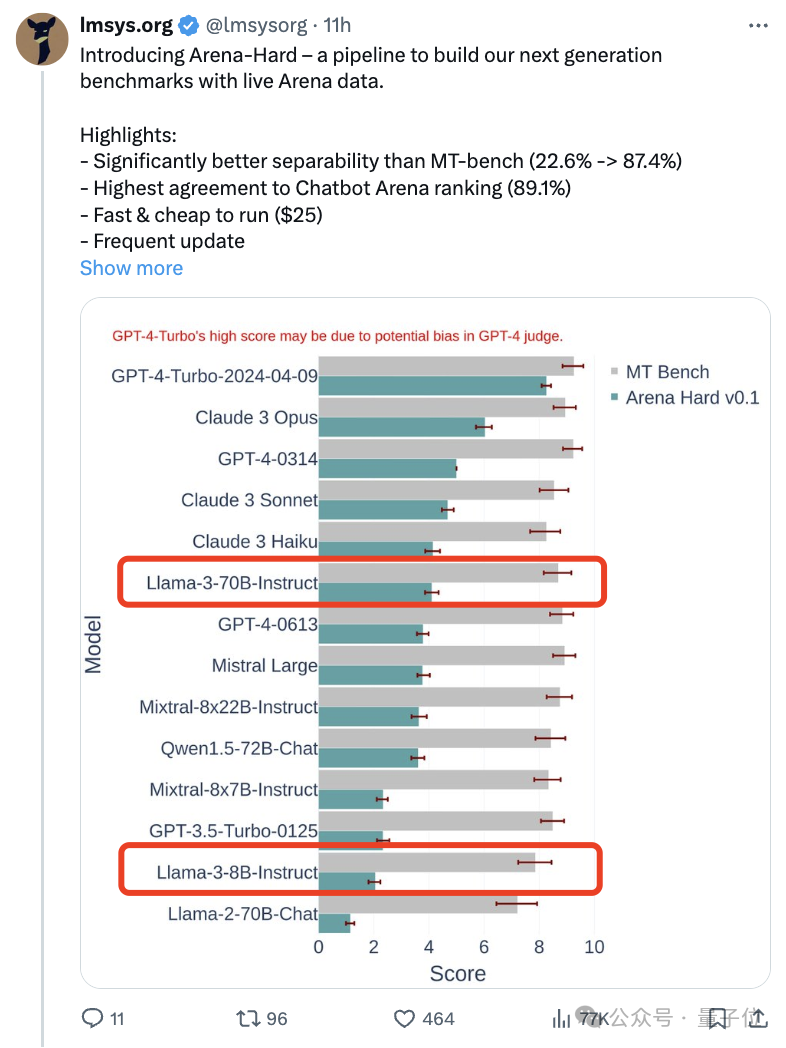
如果试题太简单,学霸和学渣都能考90分,拉不开差距……随着Claude 3、Llama 3甚至之后GPT-5等更强模型发布,业界急需一款。大模型竞技场背后组织LMSYS推出下一代基准测试,引起广泛关注。Llama 3的两个指令微调版本实力到底如何,也有了最新参考。与之前大家分数都相近的MT Bench相比,Arena-Hard,孰强孰弱一目了然。Arena-Hard利用竞技场实时人类数据构建,。
不知道李彦宏现在心情如何。就在他公开表示 “ 开源模型会越来越落后 ” 的 3 天后,活菩萨小扎慢悠悠地登场了。丝毫不给面子,以一己之力掀翻了桌子。就在今天凌晨, Meta 正式发布了全新的 Llama 3 模型,还一次上新了 8B 和 70B 两个参数版本。它的训练数据集比 Llama 2 整整大了 7 倍,达到了 15T ,容量也是上一代的两倍,支持 8K 上下文长度。目前,它们已经接入了 M
