- @2401_84164503
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
rsync和scp区别:用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。没有/opt/module/hadoop目录先创建,因为是使用hadoop普通用户,把hadoop目录的所属用户改为hadoop。(1)选中node1用来克隆出node2和node3主机,点击 虚拟机–>管理–>克隆。验证从node1发起ssh登录到node2,过程中不需要登录密码为配置成功。这里以C

完成之后登录本机出现提示后输入‘yes’,然后输入密码就可以登录到本机了。我们需要将ssh设置成无密码的,输入命令exit退出,然后利用ssh-keygen生成密钥( 遇到提示一直按回车),并将密钥加入授权。具体命令如下。之后输入ssh localhost 就可以直接登录了。

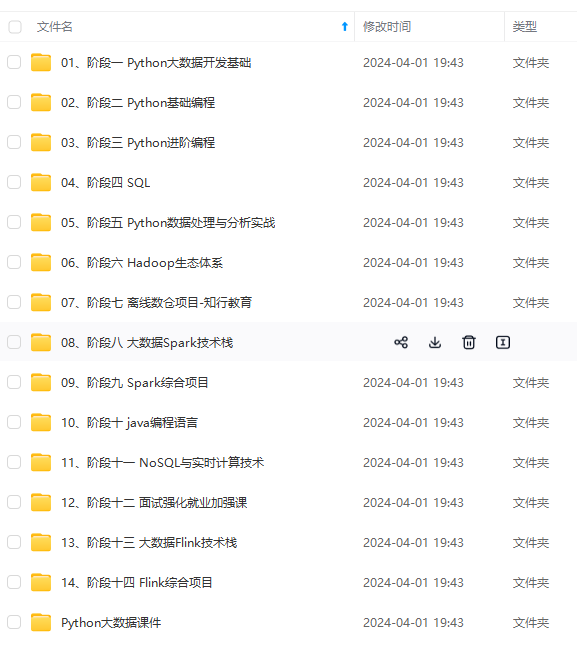
支持基于 ClickHouse 日志的实时报警功能。
由于Centos7自带的yum源中的Docker版本过低,先安装默认的版本。不删除 /var/lib/docker 目录 就不会删除已安装的镜像及容器。这是因为低版本升级到高版本之后不兼容 修改参数进行解决。
1、YOLO行人跌倒检测数据集,7500多张使用lableimg标注软件,标注好的真实场景的高质量图片数据,图片格式为jpg,标签有两种,分别为VOC格式和yolo格式,分别保存在两个文件夹中,可以直接用于YOL摔倒的行人识别,可以区分和识别到跌倒的行人和正常的行人,数据场景丰富,类别名为跌倒fall和正常状态的行人person,一共两个类别。从自动驾驶KITTI数据集中提取得到,类别为car,标

下图我们用的就多了,直角也就是90°的角,是个拼在一起编程了一个直角坐标系,这里是分象限的,这个如果不记得象限就该挨数学老师的打了。为了便于描述坐标平面内点的位置,把坐标平面被x轴和y轴分割而成的四个部分,分别叫做第一象限、第二象限、第三象限、第四象限。点的坐标用(a,b)表示,其顺序是横坐标在前,纵坐标在后,中间有“,”分开,横、纵坐标的位置不能颠倒。点P(x,y)既在x轴上,又在y轴上<=>x

【代码】FlinkSQL学习笔记(三)常用连接器举例(1),大数据开发都没弄明白凭什么拿高薪。

就全球市场来看亚马逊云科技长期处于领先地位,大概占据全球三分之一市场份额。云时代的到来,正是因为亚马逊于2006发布全球第一个云计算服务Amazon S3后,至此开启了云计算新时代,全球IT架构发现重大变革,传统IT结构向云构架转变。到如今云计算已成为全球重要基础设施,云无处不在,学习云计算相关知识就显得尤为重要,而亚马逊就是非常好的一个选择。入门资源中心:从0到1 轻松上手云服务,内容涵盖:成本

1、YOLO行人跌倒检测数据集,7500多张使用lableimg标注软件,标注好的真实场景的高质量图片数据,图片格式为jpg,标签有两种,分别为VOC格式和yolo格式,分别保存在两个文件夹中,可以直接用于YOL摔倒的行人识别,可以区分和识别到跌倒的行人和正常的行人,数据场景丰富,类别名为跌倒fall和正常状态的行人person,一共两个类别。从自动驾驶KITTI数据集中提取得到,类别为car,标
保证元素间有基本的间距,是最基本的设计技巧。文本是站点的主要内容载体;字体设计自然也是重中之重。既然我们在讲设计体系,以一致性为目标。那么同样地,我们也要把站点所使用的字号字重等范围框定在数十个选项中。数十个是个,大部分情况下应该都能满足。只要场景够特殊,特殊字体完全可以再加。